Pytorch学习:Task4 PyTorch激活函数原理和使用
Pytorch學(xué)習(xí):Task4 PyTorch激活函數(shù)原理和使用
- 1.torch.nn.ELU Sigmoid和ReLU結(jié)合體,具有左側(cè)軟飽和性
- 2.torch.nn.LeakyReLU
- 數(shù)學(xué)表達(dá)式: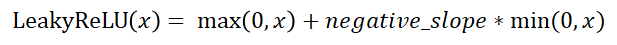
- 圖像:
- 3.torch.nn.PReLU() ReLU和LReLU改進(jìn)版本
- 數(shù)學(xué)表達(dá)式:
- 圖像
- 4.torch.nn.ReLU() CNN中最常用的
- 數(shù)學(xué)表達(dá)式:
- 圖像
- 優(yōu)缺點(diǎn)
- 5.torch.nn.ReLU6()
- 數(shù)學(xué)表達(dá)式
- 圖像
- 6.torch.nn.Sigmoid()
- 數(shù)學(xué)表達(dá)式
- 圖像
- 優(yōu)缺點(diǎn)
- 7.torch.nn.Tanh
- 數(shù)學(xué)公式:
- 圖像
- 優(yōu)缺點(diǎn)
- 激活函數(shù)的選擇
- 小練習(xí)
參考鏈接1
參考鏈接2
1.torch.nn.ELU Sigmoid和ReLU結(jié)合體,具有左側(cè)軟飽和性
數(shù)學(xué)表達(dá)式:
圖像:
右側(cè)線性部分使得ELU可以緩解梯度消失問(wèn)題,而左側(cè)軟飽和性能讓ELU對(duì)輸入變化或噪聲更魯棒。
而且ELU的輸出均值接近于0,所以沒(méi)有嚴(yán)重的偏移現(xiàn)象,所以收斂速度更快
2.torch.nn.LeakyReLU
數(shù)學(xué)表達(dá)式:
negative_slop是一個(gè)超參數(shù),控制x為負(fù)數(shù)時(shí)斜率的角度,默認(rèn)1e-2
圖像:
3.torch.nn.PReLU() ReLU和LReLU改進(jìn)版本
數(shù)學(xué)表達(dá)式:
圖像
針對(duì)x<0的硬飽和問(wèn)題,我們對(duì)ReLU作出改進(jìn),提出Leaky-ReLU,即在x<0部分添加一個(gè)參數(shù)α,如上圖所示。
P-ReLU則認(rèn)為α也應(yīng)當(dāng)作為一個(gè)參數(shù)來(lái)學(xué)習(xí),一般建議α初始化為0.25。
4.torch.nn.ReLU() CNN中最常用的
數(shù)學(xué)表達(dá)式:
圖像
優(yōu)缺點(diǎn)
優(yōu)點(diǎn):
(1)收斂速度比 sigmoid 和 tanh 快;(梯度不會(huì)飽和,解決了梯度消失問(wèn)題)
(2)計(jì)算復(fù)雜度低,不需要進(jìn)行指數(shù)運(yùn)算
缺點(diǎn):
(1)ReLu的輸出不是zero-centered;
(2)Dead ReLU Problem(神經(jīng)元壞死現(xiàn)象):某些神經(jīng)元可能永遠(yuǎn)不會(huì)被激活,導(dǎo)致相應(yīng)參數(shù)不會(huì)被更新(在負(fù)數(shù)部分,梯度為0)。產(chǎn)生這種現(xiàn)象的兩個(gè)原因:參數(shù)初始化問(wèn)題;learning rate太高導(dǎo)致在訓(xùn)練過(guò)程中參數(shù)更新太大。解決辦法:采用Xavier初始化方法;以及避免將learning rate設(shè)置太大或使用adagrad等自動(dòng)調(diào)節(jié)learning rate的算法。
(3)ReLu不會(huì)對(duì)數(shù)據(jù)做幅度壓縮,所以數(shù)據(jù)的幅度會(huì)隨著模型層數(shù)的增加不斷擴(kuò)張。
5.torch.nn.ReLU6()
數(shù)學(xué)表達(dá)式
圖像
6.torch.nn.Sigmoid()
數(shù)學(xué)表達(dá)式
圖像
優(yōu)缺點(diǎn)
優(yōu)點(diǎn):
(1)便于求導(dǎo)的平滑函數(shù)
(2)能壓縮數(shù)據(jù),保證數(shù)據(jù)幅度不會(huì)有問(wèn)題
(3)適合用于前向傳播
缺點(diǎn):【梯度消失/冪運(yùn)算耗時(shí)】
(1)容易出現(xiàn)梯度消失(gradient vanishing)的現(xiàn)象:當(dāng)激活函數(shù)接近飽和區(qū)時(shí),變化太緩慢,導(dǎo)數(shù)接近0,根據(jù)后向傳遞的數(shù)學(xué)依據(jù)是微積分求導(dǎo)的鏈?zhǔn)椒▌t,當(dāng)前導(dǎo)數(shù)需要之前各層導(dǎo)數(shù)的乘積,幾個(gè)比較小的數(shù)相乘,導(dǎo)數(shù)結(jié)果很接近0,從而無(wú)法完成深層網(wǎng)絡(luò)的訓(xùn)練。
(2)Sigmoid的輸出不是0均值的:這會(huì)導(dǎo)致后層的神經(jīng)元的輸入是非0均值的信號(hào),這會(huì)對(duì)梯度產(chǎn)生影響。以 f=sigmoid(wx+b)為例, 假設(shè)輸入均為正數(shù)(或負(fù)數(shù)),那么對(duì)w的導(dǎo)數(shù)總是正數(shù)(或負(fù)數(shù)),這樣在反向傳播過(guò)程中要么都往正方向更新,要么都往負(fù)方向更新,導(dǎo)致有一種捆綁效果,使得收斂緩慢。
(3)冪運(yùn)算相對(duì)耗時(shí)
7.torch.nn.Tanh
本質(zhì)是sigmoid的變型,tanh(x)=2sigmoid(2x)-1
數(shù)學(xué)公式:
或
圖像
優(yōu)缺點(diǎn)
改善:將輸出值映射到了-1到1之間,因此它是0均值的了
缺點(diǎn):梯度消失和冪運(yùn)算耗時(shí)長(zhǎng)
激活函數(shù)的選擇
最好不要用sigmoid,tanh也是不適用的,其會(huì)導(dǎo)致梯度消失問(wèn)題。使用relu函數(shù),要小心設(shè)置learning rate。還有其他的激活函數(shù),如leaky relu、prelu和maxout等等,可以優(yōu)先選擇relu,如果出現(xiàn)Dead ReLU Problem,應(yīng)該使用leaky relu、prelu和maxout。
小練習(xí)
在pytorch中手動(dòng)實(shí)現(xiàn)上述激活函數(shù)
class ActivateFunction():def __init__(self):passdef relu(self,x):return max(0,x)def relu6(self,x):return min(max(0,x),6)def sigmoid(self,x):return 1/(1+math.exp(-x))def celu(self,x):return max(0,x) + min(0,a*(math.exp(x/a)-1))def logsigmoid(self,x):return math.log(1/(1+math.exp(-x)))def tanh(self,x):return (math.exp(x) - math.exp(-x))/(math.exp(x)+math.exp(-x))def prelu(self,x,a):return max(0,x)+a*min(0,x)def leakyrelu(self,x,negative_slope=1e-2):return max(0,x)+negative_slope*min(0,x)def elu(self,x,a):return max(0,x) + min(0,a*(math.exp(x)-1))def softshrink(x,l):if x>l:return x-lelif x<l:return x+lelse:return 0總結(jié)
以上是生活随笔為你收集整理的Pytorch学习:Task4 PyTorch激活函数原理和使用的全部?jī)?nèi)容,希望文章能夠幫你解決所遇到的問(wèn)題。

- 上一篇: Pytorch学习 - Task6 Py
- 下一篇: Pytorch使用过程错误与解决 -汇总