【NLP】使用堆叠双向 LSTM 进行情感分析
作者 | SRIVIGNESH_R??編譯 | Flin? ?來源 | analyticsvidhya
情緒分析
情感分析是發現文本數據的情感的過程。情感分析屬于自然語言處理中的文本分類。情緒分析將幫助我們更好地了解我們的客戶評論。
情緒的性質有:正面、負面和中性。當我們分析產品的負面評論時,我們可以使用這些評論來克服我們面臨的問題并提供更好的產品。
使用情感分析的好處包括:
更好地了解客戶
根據客戶評論改進產品功能
我們將能夠識別功能中的錯誤并解決它們以使客戶滿意。
情感分析可以通過兩種不同的方式進行:
基于規則的情感分析
自動化情緒分析
在基于規則的情感分析中,我們定義了一組規則,如果數據滿足這些規則,那么我們可以對它們進行相應的分類。
例如,如果文本數據包含好、漂亮、驚人等詞,我們可以將其歸類為積極情緒。基于規則的情感分析的問題在于它不能很好地概括并且可能無法準確分類。
例如,基于規則的系統更有可能根據規則將以下句子歸類為正面,“The product is not good”。原因是基于規則的系統識別出句子中的單詞 good 并將其歸類為積極情緒,但上下文不同,句子是消極的。
為了克服這些問題,我們可以使用深度學習技術進行情感分析。
在自動情感分析中,我們利用深度學習來學習數據中的特征-目標映射。在我們的例子中,特征是評論,目標是情緒。因此,在我們的文章中,我們使用深度學習模型來進行自動情感分析。
使用 TensorFlow 進行情感分析
在這篇文章中,我們將利用深度學習來發現 IMDB 評論的情緒。我們將在這篇文章中使用 IMDB 評論數據。你可以在此處(https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews)下載數據。
數據包含兩列,即評論和情緒。情緒列僅包含兩個值,即正面和負面,表示相應評論的情緒。所以我們可以推斷我們的問題是一個二元分類問題。我們的模型將學習特征-目標映射,在我們的例子中,它是評論-情緒映射。
在這篇文章中,我們將使用 regex 和 spaCy 進行預處理,使用 TensorFlow 的雙向 LSTM 模型進行訓練。
要安裝 spaCy,請參閱此(https://spacy.io/usage#installation)網頁以獲取說明。
要安裝 TensorFlow,請參閱此(https://www.tensorflow.org/install)網頁以獲取說明。
安裝 spaCy 后,使用以下命令下載名為 en_core_web_sm 的 spaCy 的訓練管道包,我們將使用它進行預處理。
python?-m?spacy?download?en_core_web_sm導入所需的庫
import?re import?spacy import?numpy?as?np import?pandas?as?pd import?en_core_web_sm import?tensorflow?as?tf from?nltk.stem?import?WordNetLemmatizer from?tensorflow.keras.optimizers?import?Adam from?tensorflow.keras.models?import?Sequential from?spacy.lang.en.stop_words?import?STOP_WORDS from?tensorflow.keras.preprocessing.text?import?Tokenizer from?tensorflow.keras.preprocessing.sequence?import?pad_sequences from?tensorflow.keras.layers.experimental.preprocessing?import?TextVectorization from?tensorflow.keras.layers?import?Embedding,?LSTM,?Dense,?Bidirectional,?Dropout nlp?=?en_core_web_sm.load() lemmatizer?=?WordNetLemmatizer() stopwords?=?STOP_WORDS EMOJI_PATTERN?=?re.compile("["u"U0001F600-U0001F64F"??#?emoticonsu"U0001F300-U0001F5FF"??#?symbols?&?pictographsu"U0001F680-U0001F6FF"??#?transport?&?map?symbolsu"U0001F1E0-U0001F1FF"??#?flags?(iOS)u"U00002702-U000027B0"u"U000024C2-U0001F251""]+",?flags=re.UNICODE ) FILTERS?=?'!"#$%&()*+,-/:;?@[\]^_`{|}~tn' HTML_TAG_PATTERN?=?re.compile(r']*>') NUMBERING_PATTERN?=?re.compile('d+(?:st|[nr]d|th)') DISABLE_PIPELINES?=?["tok2vec",?"parser",?"ner",?"textcat",?"custom",?"lemmatizer"]我們正在使用命令 en_core_web_sm.load() 加載 spaCy 的訓練管道 en_core_web_sm。我們還加載了 spaCy 中可用的停用詞。停用詞是沒有太多意義的詞,一些例子包括像 the、he、she、it 等詞。
上面定義的表情符號模式EMOJI_PATTERN用于刪除評論數據中的表情符號。
上面定義的過濾器FILTERS是評論中可能提供的特殊字符。
上面定義的 HTML 標記模式(HTML_TAG_PATTERN)用于刪除 HTML 標記并僅保留標記內的數據。
上面定義的編號模式NUMBERING_PATTERN用于刪除編號,如 1st、2nd、3rd 等。
上面定義的禁用管道DISABLE_PIPELINES用于禁用 spaCy 語言模型中的某些管道,從而高效且低延遲地完成處理。
def?initial_preprocessing(text):"""-?Remove?HTML?tags-?Remove?Emojis-?For?numberings?like?1st,?2nd-?Remove?extra?characters?>?2?eg:ohhhh?to?ohh"""tag_removed_text?=?HTML_TAG_PATTERN.sub('',?text)emoji_removed_text?=?EMOJI_PATTERN.sub(r'',?tag_removed_text)numberings_removed_text?=??NUMBERING_PATTERN.sub('',?emoji_removed_text)extra_chars_removed_text?=?re.sub(r"(.)1{2,}",??r'11',?numberings_removed_text)return?extra_chars_removed_textdef?preprocess_text(doc):"""Removes?the?1.?Spaces2.?Email3.?URLs4.?Stopwords5.?Punctuations6.?Numbers"""tokens?=?[tokenfor?token?in?docif?not?token.is_space?andnot?token.like_email?andnot?token.like_url?andnot?token.is_stop?andnot?token.is_punct?andnot?token.like_num]"""Remove?special?characters?in?tokens?except?dot(would?be?useful?for?acronym?handling)"""translation_table?=?str.maketrans('',?'',?FILTERS)translated_tokens?=?[token.text.lower().translate(translation_table)for?token?in?tokens]"""Remove?integers?if?any?after?removing?special?characters,?remove?single?characters?and?lemmatize"""lemmatized_tokens?=?[lemmatizer.lemmatize(token)for?token?in?translated_tokensif?len(token)?>?1]return?lemmatized_tokenslabels?=?imdb_data['sentiment'].iloc[:10000]labels?=?labels.map(lambda?x:?1?if?x=='positive'?else?0)"""Preprocess?the?text?data"""data?=?imdb_data.iloc[:10000,?:]column?=?'review'not_null_data?=?data[data .notnull()]not_null_data=?not_null_data .apply(initial_preprocessing)texts?=?[preprocess_text(doc)for?doc?in?nlp.pipe(not_null_data ,?disable=DISABLE_PIPELINES)]上面的代碼是如何工作的?
首先,我們取前 10000 行數據。此數據中的目標是名為“情緒”的列。情緒列由兩個值組成,即“正面”和“負面”,表示相應評論的情緒。
我們用整數 1 替換值“正”,用整數 0 替換值“負”。
我們只取非空的行,這意味著我們忽略了具有空值的評論。在獲得非空評論后,我們應用上面定義的初始預處理函數。
方法初始預處理后的步驟是,
刪除 HTML 標簽,如 ,并提取標簽內定義的數據
刪除數據中的表情符號
刪除數據中的編號模式,如 1st、2nd、3rd 等。
刪除單詞中的多余字符。例如,單詞 ohhh 被替換為 ohh。
在應用初始預處理步驟后,我們使用 spacy 來預處理數據。預處理方法遵循的步驟是,
刪除數據中的空格。
刪除數據中的電子郵件。
刪除數據中的停用詞。
刪除數據中的 URL。
刪除數據中的標點符號。
刪除數據中的數字。
詞形還原。
函數 nlp.pipe 將在 spaCy 中生成一系列 doc 對象。spaCy 中的文檔是一系列令牌對象。我們使用禁用管道來加快預處理時間。
詞形還原是尋找詞根的過程。例如,單詞 running 的詞根是 run。進行詞形還原的目的是減少詞匯量。為了使單詞詞形還原,我們使用了 nltk 包中的 WordNetLemmatizer。
tokenizer?=?Tokenizer(filters=FILTERS,lower=True ) padding?=?'post' tokenizer.fit_on_texts(texts) vocab_size?=?len(tokenizer.word_index)?+?1 sequences?=?[] max_sequence_len?=?0 for?text?in?texts:#?convert?texts?to?sequencetxt_to_seq?=?tokenizer.texts_to_sequences([text])[0]sequences.append(txt_to_seq)#?find?max_sequence_len?for?paddingtxt_to_seq_len?=?len(txt_to_seq)if?txt_to_seq_len?>?max_sequence_len:max_sequence_len?=?txt_to_seq_len #?post?padding padded_sequences?=?pad_sequences(sequences,?maxlen=max_sequence_len,?padding=padding )執行預處理后,我們將對數據進行標記化,將標記化的單詞轉換為序列,并填充標記化的句子。標記化是將句子分解為單詞序列的過程。
例如,“我喜歡蘋果”可以標記為 [“我”,“喜歡”,“蘋果”]。將標記化的句子轉換為序列看起來像 [1, 2, 3]。單詞“i”、“like”和“apples”被映射到數字 1、2 和 3。然后填充序列看起來像 [1, 2, 3, 0, 0, 0]。數字 3 后面的三個零是填充序列。這也稱為后填充。
model?=?Sequential() model.add(Embedding(vocab_size,?64,?input_length=max_sequence_len-1)) model.add(Bidirectional(LSTM(64,?return_sequences=True,?input_shape=(None,?1)))) model.add(Dropout(0.2)) model.add(Bidirectional(LSTM(32))) model.add(Dropout(0.2)) model.add(Dense(64,?activation='relu')) model.add(Dropout(0.1)) model.add(Dense(1,?activation='sigmoid')) adam?=?Adam(learning_rate=0.01) model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),?optimizer=adam,?metrics=['accuracy'] ) model.summary()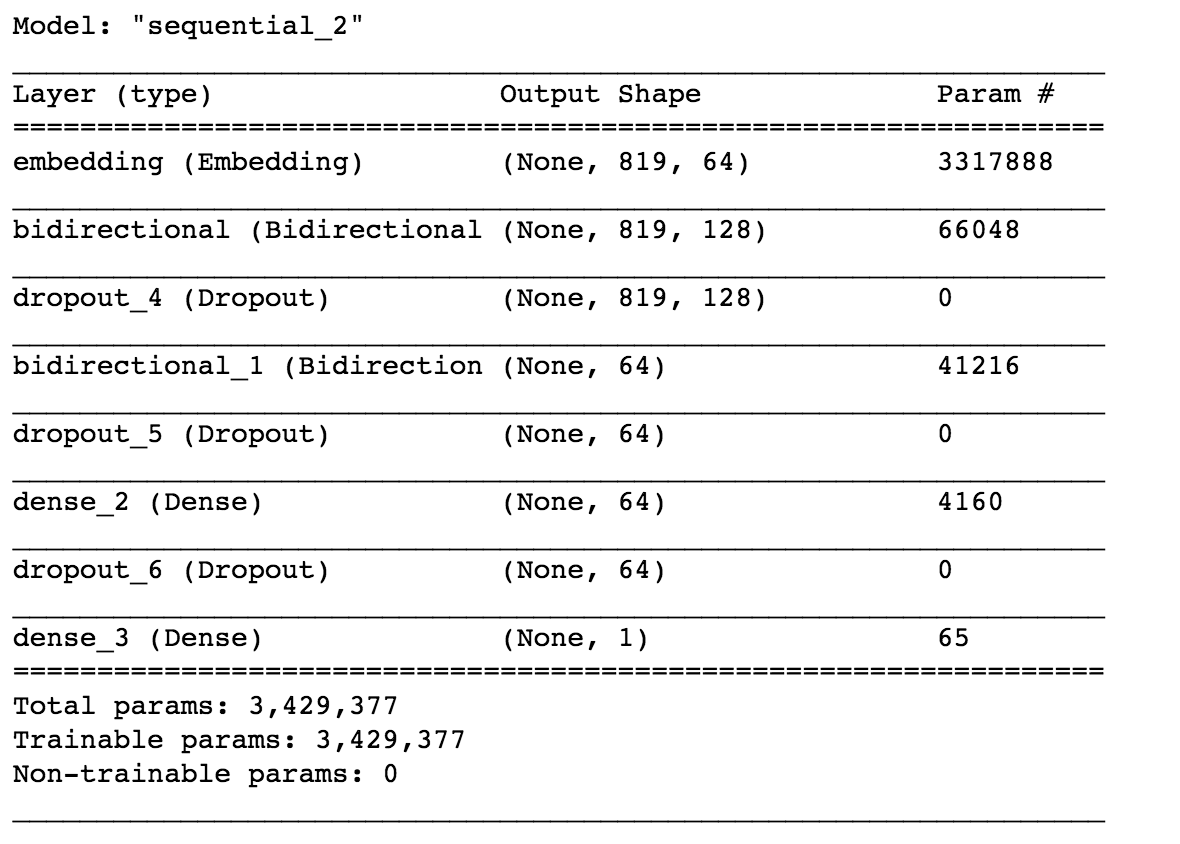
這里我們使用了使用 TensorFlow 的雙向 LSTM 模型。讓我們深入了解模型的工作原理。
首先,我們定義了一個嵌入層。嵌入層將單詞轉換為詞向量。例如,單詞“apple”可以嵌入為 [0.2, 0.12, 0.45]。維數是一個超參數。
使用詞嵌入的目的是在詞之間找到更好的相似性,這是獨熱編碼失敗的地方。這里我們選擇了維度64。
我們在這里使用的模型是堆疊的雙向 LSTM。第一個雙向層定義為 64 個單元,第二層定義為 32 個雙向 LSTM 單元。
之后,我們使用了具有 64 個單元的 Dense 層和激活函數 ReLU。最后一層是具有 sigmoid 激活函數的輸出層,因為我們的問題是一個二元分類問題,我們使用了 sigmoid 函數。我們還使用了 Dropout 層來防止過度擬合。
我們使用 Adam 優化函數進行反向傳播,并使用二元交叉熵損失函數進行度量的損失和準確性。損失函數用于優化模型,而度量用于我們的比較。要了解有關 LSTM 工作的更多信息,請參閱此博客:https://colah.github.io/posts/2015-08-Understanding-LSTMs/
history?=?model.fit(padded_sequences,?labels.values,?epochs=10,verbose=1,batch_size=64 )現在是時候訓練模型了。我們使用了 10 個 epoch 和 64 的批量來訓練。我們使用評論的填充序列作為特征,將情感作為目標。

import?matplotlib.pyplot?as?plt fig?=?plt.plot(history.history['accuracy']) title?=?plt.title("History") xlabel?=?plt.xlabel("Epochs") ylabel?=?plt.ylabel("Accuracy")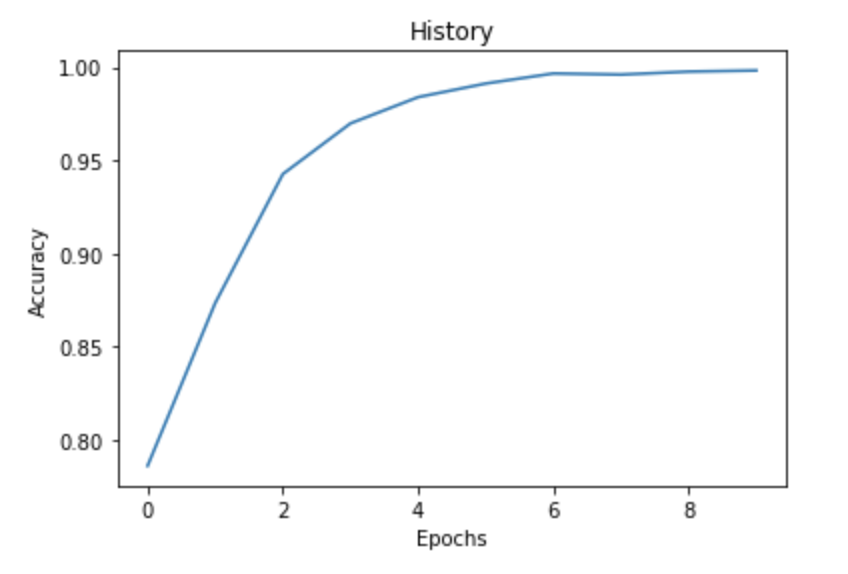
如果我們繪制歷史記錄,我們可以清楚地看到,隨著epoch的增加,我們的準確性也會提高。我們獲得了 99.82% 的準確率。
現在我們已經訓練了我們的模型,我們可以用它來進行預測。
predictions?=?model.predict(padded_sequences[:4]) for?pred?in?predictions:print(pred[0])我們使用了前四篇經過預處理和預測的評論。我們正在獲得以下結果。
Output 0.99986255 0.9999008 0.99985176 0.00030466914輸出表示積極情緒的概率。讓我們檢查一下這是否正確。

這些預測非常令人印象深刻。通過這種方式,你可以利用 TensorFlow 進行情感分析。
總結
在這篇文章中,我們了解了基于規則的情感分析和自動情感分析之間的區別。此外,我們利用深度學習的自動化情感分析來分析情感。
使用 spaCy 預處理數據。使用標記器將文本轉換為序列。
使用堆疊雙向 LSTM 訓練數據
訓練后繪制歷史
使用經過訓練的模型進行預測
隨意調整模型的超參數,例如更改優化器函數、添加額外層、更改激活函數,并嘗試增加嵌入向量中的維度。這樣,你將能夠獲得更精細,更精細的結果。
往期精彩回顧適合初學者入門人工智能的路線及資料下載機器學習及深度學習筆記等資料打印機器學習在線手冊深度學習筆記專輯《統計學習方法》的代碼復現專輯 AI基礎下載黃海廣老師《機器學習課程》視頻課黃海廣老師《機器學習課程》711頁完整版課件本站qq群554839127,加入微信群請掃碼:
總結
以上是生活随笔為你收集整理的【NLP】使用堆叠双向 LSTM 进行情感分析的全部內容,希望文章能夠幫你解決所遇到的問題。

- 上一篇: 【学术相关】U.S.News正式发布最新
- 下一篇: c:forecah 参数param 不