人工智能在线特征系统中的生产调度
在上篇博客《人工智能在線特征系統中的數據存取技術》中,我們圍繞著在線特征系統存儲與讀取這兩方面話題,針對具體場景介紹了一些通用技術,此外特征系統還有另一個重要話題:特征生產調度。本文將以美團點評酒旅在線特征系統為原型,介紹特征生產調度的架構演進及核心技術。架構演進共包含三個階段,不同階段面臨的需求痛點和挑戰各有不同,包括導入并發控制、特征變更原子切換、實時特征計算框架涉及、實時與離線調度融合等。本文我們將從業務需求角度出發,介紹系統演進的三個階段所解決的主要問題和技術手段,然后把系統演化過程中的一些常見問題和解決方案抽象出來,放在特征生產技術章節統一討論。
從離線到在線
在線特征系統最核心的目標是將離線的特征數據通過在線服務的方式,提供給策略系統使用。在線特征系統的出現是為了實現如下的系統目標:
- 將離線的特征數據,以接口訪問的形式提供給線上策略系統使用
- 特征數據每日更新一次
- 支撐的數據量在百億級以上,可以水平擴展
- 每秒特征訪問量峰值達到百萬,平均響應延遲在20ms以內
從整體系統功能上來劃分,在線特征系統需要做兩件事情:第一,每日將離線更新的特征數據寫入到存儲引擎,這里我們選用分布式KV(Key-Value)存儲引擎Tair作為線上存儲引擎,利用公司的ETL工具定期將離線數據寫入到Tair;第二,提供接口服務,我們搭建了一個基于Thrift接口協議的RPC服務來對外提供特征讀取服務。
由于不同特征集查詢方式都相同,只是數據不同,因此在Service層我們把一組特征集合以及它的查詢維度抽象成Domain。舉個例子,Domain=ABC表示用戶基礎畫像特征,包含性別、年齡、星座等特征,同時它又定義了查詢維度為用戶ID。這樣對于不同的特征集,只需要調用同一個接口,傳入不同的Domain即可。
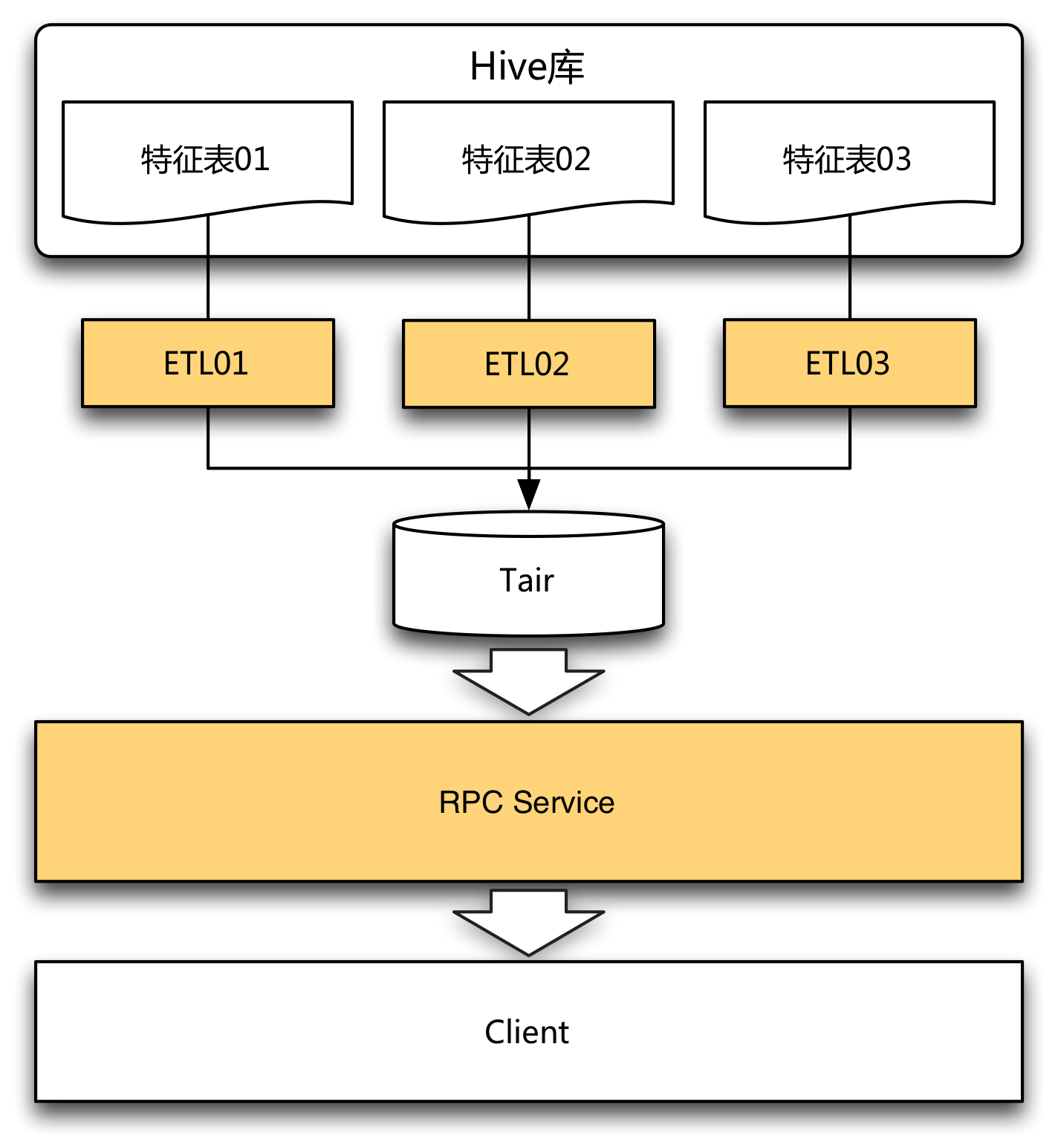
從離線到在線在這一階段,系統的重點是搭建一套特征導入、存儲、讀取的流程。我們利用公司提供的工具和組件迅速完成了任務。當有新的特征表需要接入時,開發一個導入ETL,在服務端做相應的配置即可生效。同時,結構上的松散也帶來很大的靈活性。在業務發展初期,團隊組織結構單一,需求量少,變化快,種類多,系統保持簡單、松耦合,有助于靈活應對不斷變化的需求。
從手動到自動
隨著每日接入Domain數量的增加,接入新Domain工作顯得繁瑣而效率低下:每接入一個新的特征表,需要開發ETL,而且ETL需要測試、上線、配置調度。因此,我們重新設計了數據導入的方案。
元數據驅動,平臺化導入
ETL工具需要開發數據導入腳本,它的靈活性相對較高,寫出錯的可能性也很大,測試和審核流程難以避免,新入職同學更是需要較大的學習成本。而對于特征導入這個需求,它的模式固化,可以抽取出以下元數據:
- 數據源信息:離線數據庫、表名稱等。
- 存儲引擎信息:引擎類型、機房、IP等。
- 存儲格式信息:Key字段、Value字段等。
- 特征更新信息:更新周期、分區字段、分區方式等。
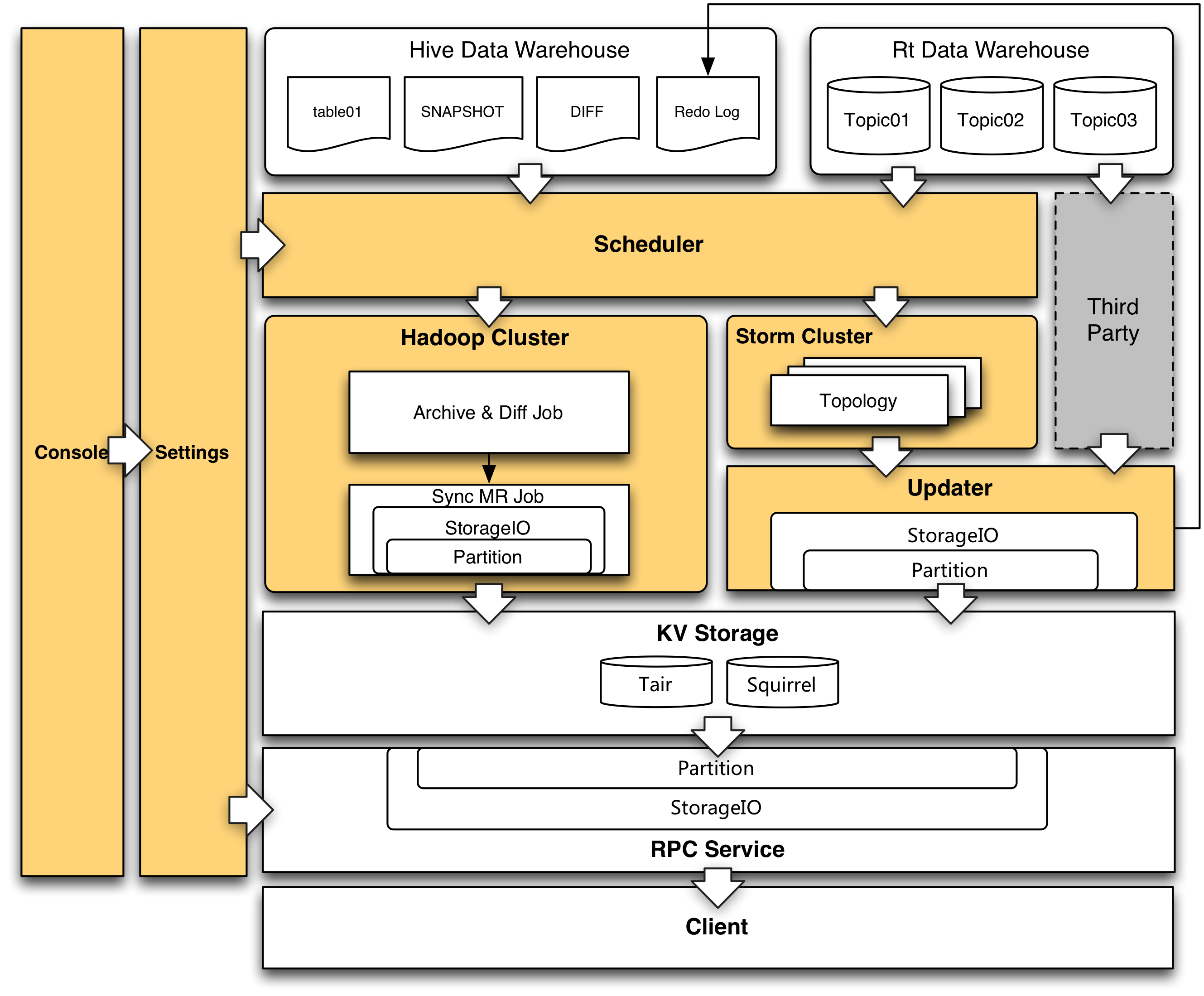
根據這些元數據,將導入流程都固化下來,可以進行平臺化的統一調度。用戶通過填寫或選擇少量的表單信息注冊任務,出錯的可能性大大降低,流程也可以從原來的寫ETL代碼、測試作業、配置調度、上線審核,簡化成了填寫表單和審核。接入流程從原來的幾個小時,縮短到幾分鐘。同時,存儲引擎從原來的僅支持Tair,到現在Squirrel(美團點評基于Redis的KV分布式存儲中間件)等多引擎加入,系統調度架構如下。
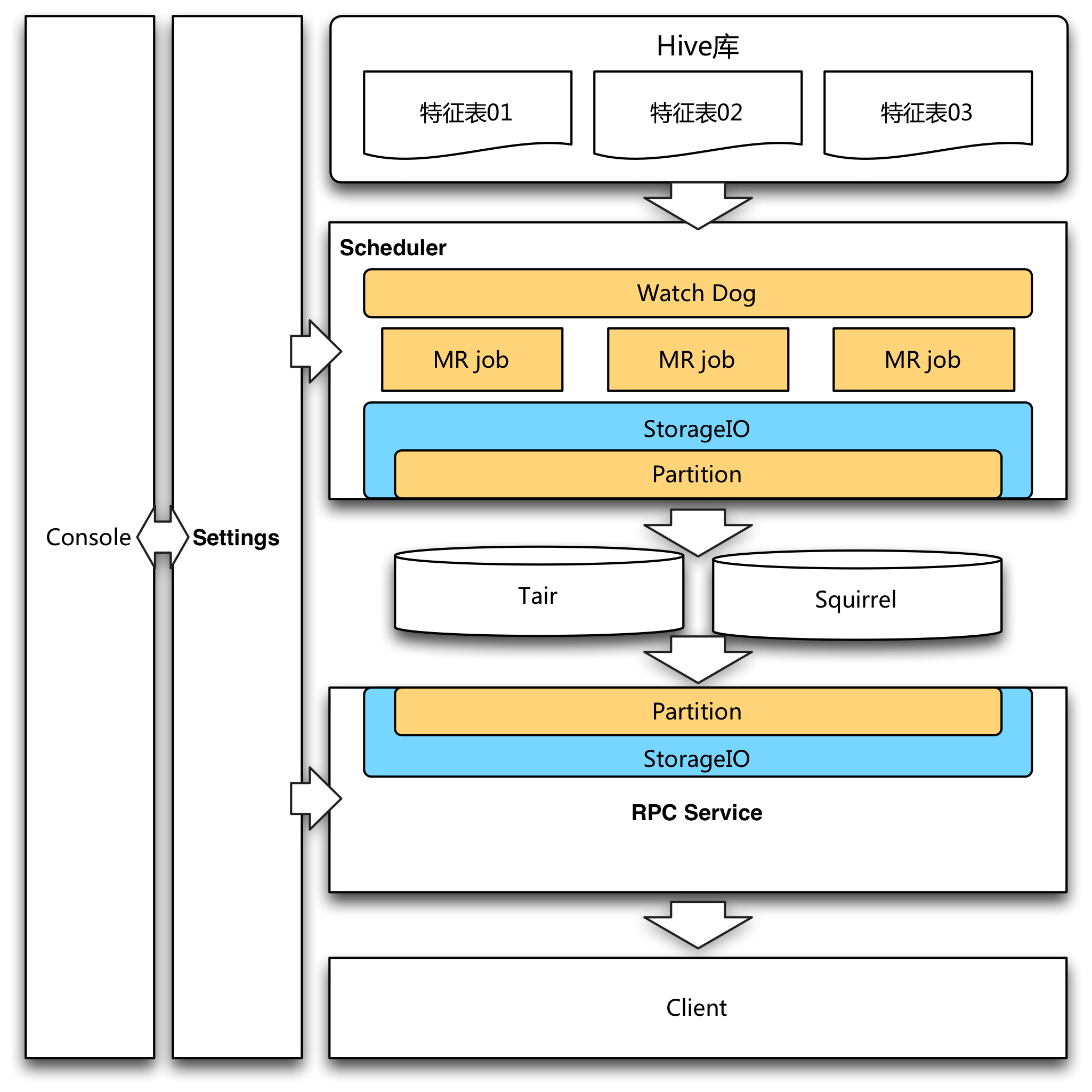
離線特征生產調度- 控制臺(Console)是元數據的入口,用戶在這里完成表單的填寫,元數據落入Settings模塊的MySQL庫中。
- 調度模塊(Scheduler)從Settings模塊讀取元數據,每日掃描需要導入的Hive表,待當日離線數據生產完成,便會啟動Map Reduce Job來執行導入工作。
- 接口服務(Service)接收來自客戶端的請求,根據Domain名稱從Settings庫中加載Domain元數據,然后從存儲引擎取到對應的特征信息。由于調度模塊與接口服務模塊統一了元數據,因此新特征的接入可以實現服務端工作零成本,新上線的Domain可以直接從服務接口取到數據,無需任何人工操作。
階段二的完成大大簡化了離線特征的上線流程,使接入工作從幾個小時縮短到幾分鐘,也降低了出錯的可能性。導入平臺化的實現,也為通用性優化功能提供了土壤:數據壓縮功能使得內存、帶寬資源得到了更充分的利用;多引擎存儲功能滿足了需求方對性能的不同要求;導入調度功能解決了更新流量峰值的問題,提高了系統的整體可用性。
從天級到秒級
迄今為止,原始特征數據都是離線的,且更新周期都是一天,這跟離線數據倉庫的T+1模式有關。而很多關鍵的業務指標希望做到實時化,特征工程也是如此。用戶近幾分鐘、近幾秒的行為信息往往比很多離線特征更具有價值,實時特征必然會在策略系統中發揮越來越重要的作用。
參考離線特征的計算過程,離線大部分是利用了數據平臺的ETL工具,它的輸入輸出都相對固定,只能落地到Hive,用戶大部分的精力只需要關心計算邏輯。因此從離線Hive導入到線上存儲引擎,成為了特征系統的主要工作,無需操心特征計算。而目前公司沒有很完備的、類似Hive SQL的計算框架支持實時特征計算,生產計算實時特征需要自己寫流式處理作業。因此我們有必要提供一個專用、便捷的特征計算工具來支持常見特征的計算工作,利用簡單配置完成實時特征計算。
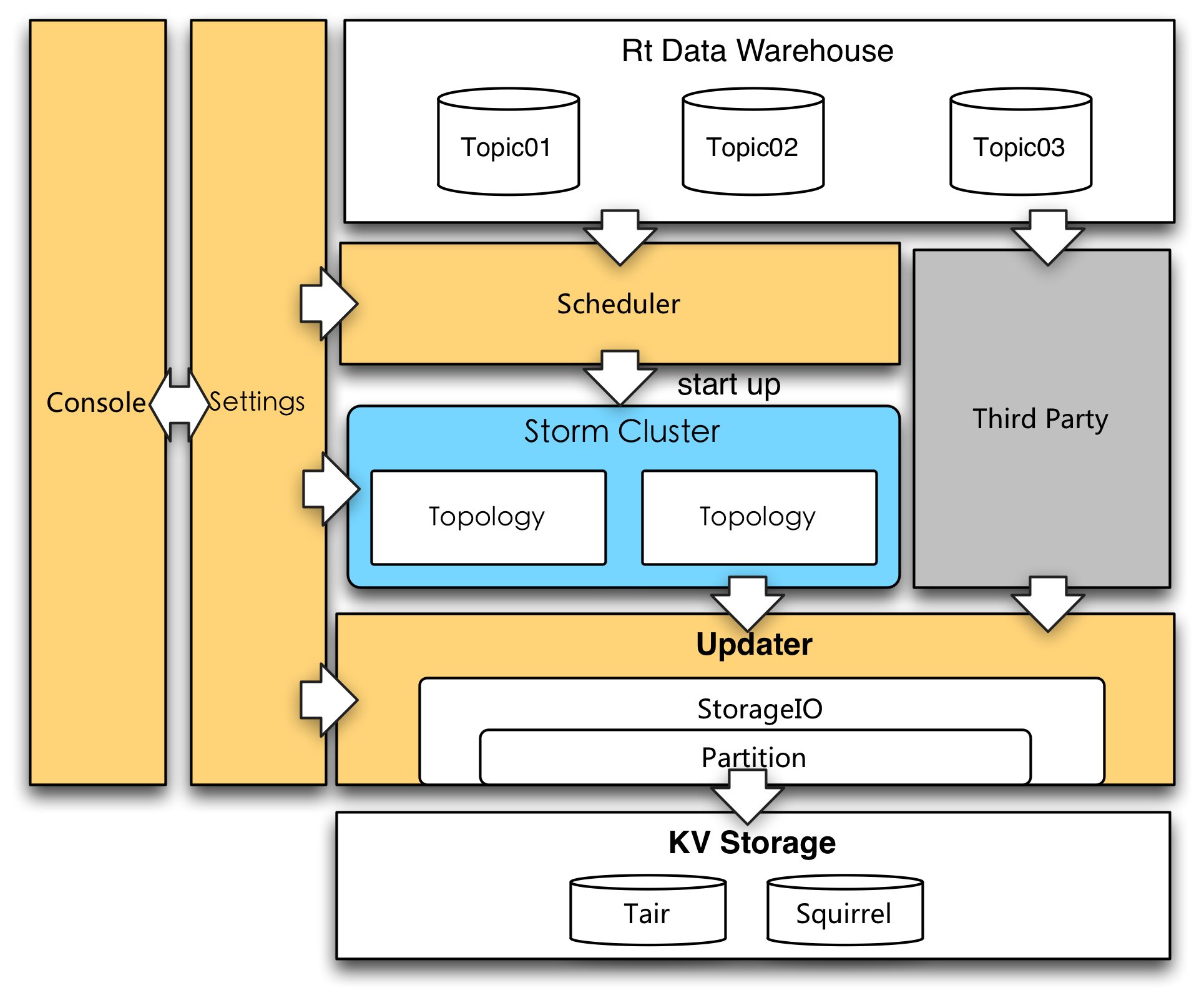
實時特征生產調度實時部分的系統架構如上圖所示,與離線類似,Console部分接受用戶的表單配置并將元數據寫入Settings持久化。Scheduler會負責讀取Settings的元數據信息調度實時特征生產任務。我們采用Storm流式服務計算實時特征,從實時數據倉庫的Kafka Topic接收流式數據,并按照預先配置好的特征計算邏輯生產、計算實時特征,然后寫入到線上存儲引擎。
下面詳細討論一下我們對于實時特征計算的平臺化以及優化方案。
實時特征計算平臺化
算法使用的特征有繁有簡,復雜多變,設計一個自動化的實時特征計算系統難度很大。回到業務需求,我們的目的是通過特征生產系統來簡化開發工作量,而非完全取代特征開發;因此我們選擇一部分常見的實時特征類型,實現自動化生產和導入。對于更復雜的實時特征,提供了更新接口來支持第三方特征生產程序對接。
以下是系統支持配置化生產的特征類型。首先是不同的時間跨度分類:
- 固定時間窗口,時間窗口的起止時間點是固定的,比如某日的銷售額。
- 滑動時間窗口,時間窗口的長度是固定的,但起止時間點一直在向前滾動,比如近2小時銷售額。
- 無限時間窗口,時間窗口的起點是固定的,但終止時間點一直在向前滾動,比如商家歷史上銷售總額。
銷售額這個指標其實是對訂單金額做求和(SUM)操作,總結常見的計算類型有如下幾種:
- 求和(SUM),如銷售額。
- 計數(COUNT),如訂單量。
- 最大值(MAX),如最大訂單金額。
- 最小值(MIN),如最小訂單金額。
- 平均數(AVG),如平均訂單金額。
- 去重計數(DISTINCT COUNT),如頁面的用戶瀏覽量(同一個用戶多次瀏覽算一次)。
- 最新值(LAST),如最后支付時間。
- 列表(LIST),如最近的支付用戶ID列表。
以上時間窗口與指標的組合,一共支持24種常見特征的計算類型。
對于實現上述特征的計算,主要包含如下三個抽象步驟: 1. 讀取相關的數據(如上次特征值,或一些中間結果)。 2. 根據收到的業務數據,以及步驟1取到的數據進行計算(如累加或求去重數),得到新的特征值(和中間結果)。 3. 將特征(和中間結果)更新到系統。
不同時間窗口的實現方式應該盡量跟計算類型解耦,可以抽象出各自的處理方式: 1. 固定時間窗口,這類特征應該將時間窗的標識放在特征的Key當中。例如某商戶某日銷售額這個特征,將Key設置成${商戶ID}_${日期},這樣可以實現時間窗的自然滾動。 2. 滑動時間窗口,常見的做法是緩存時間窗內的所有明細數據作為中間結果,當新的明細數據到來時,刪除時間窗內過期的明細數據,并利用緩存的明細數據重新計算特征值。但這種實現方式缺點是當滑動時間窗的跨度較大時,需要緩存大量中間結果,可能成為系統瓶頸。對于這個問題,我們采用了延遲隊列的實現方式。 > 延遲隊列實現滑動時間窗,當新的明細數據到來時,會直接累計到特征值,同時將明細數據發送到延遲隊列。延遲隊列的作用是可以將數據延遲指定時間后重新發送回系統。系統接收到延遲消息時,再從特征值中抵消該部分數據(例如計算近2小時銷售額,收到訂單數據后累加銷售額,收到延遲訂單消息則減去銷售額),這樣可以只保留特征值,無需緩存明細數據即可實現窗口滑動的邏輯。延遲隊列的實現方式只適用于可抵消的計算類型,如求和、計數等,但像最大值、最小值、去重計數等無法滿足 3. 無限時間窗口,簡單粗暴的方式是回溯所有歷史消息即可。然而這樣存在的問題是,第一,流式實時數據本身一般不會持久化保留太長的時間(通常是幾天);第二,這種方式太耗費資源,特征的每一次更新都涉及多次RPC。較為合適的辦法是離線數據計算特征的基準值,實時數據基于離線計算結束的時間點繼續累積。詳細過程參考下文數據融合與數據恢復。
為了保證數據可靠性與查詢效率,中間結果和特征都存放在分布式Key-Value存儲引擎中。下圖是Storm計算框架的拓撲邏輯圖,其中Calc Bolt承擔著不同計算類型的實現,而Mafka Delay Topic則是延遲隊列組件,用于實現滑動時間窗口。
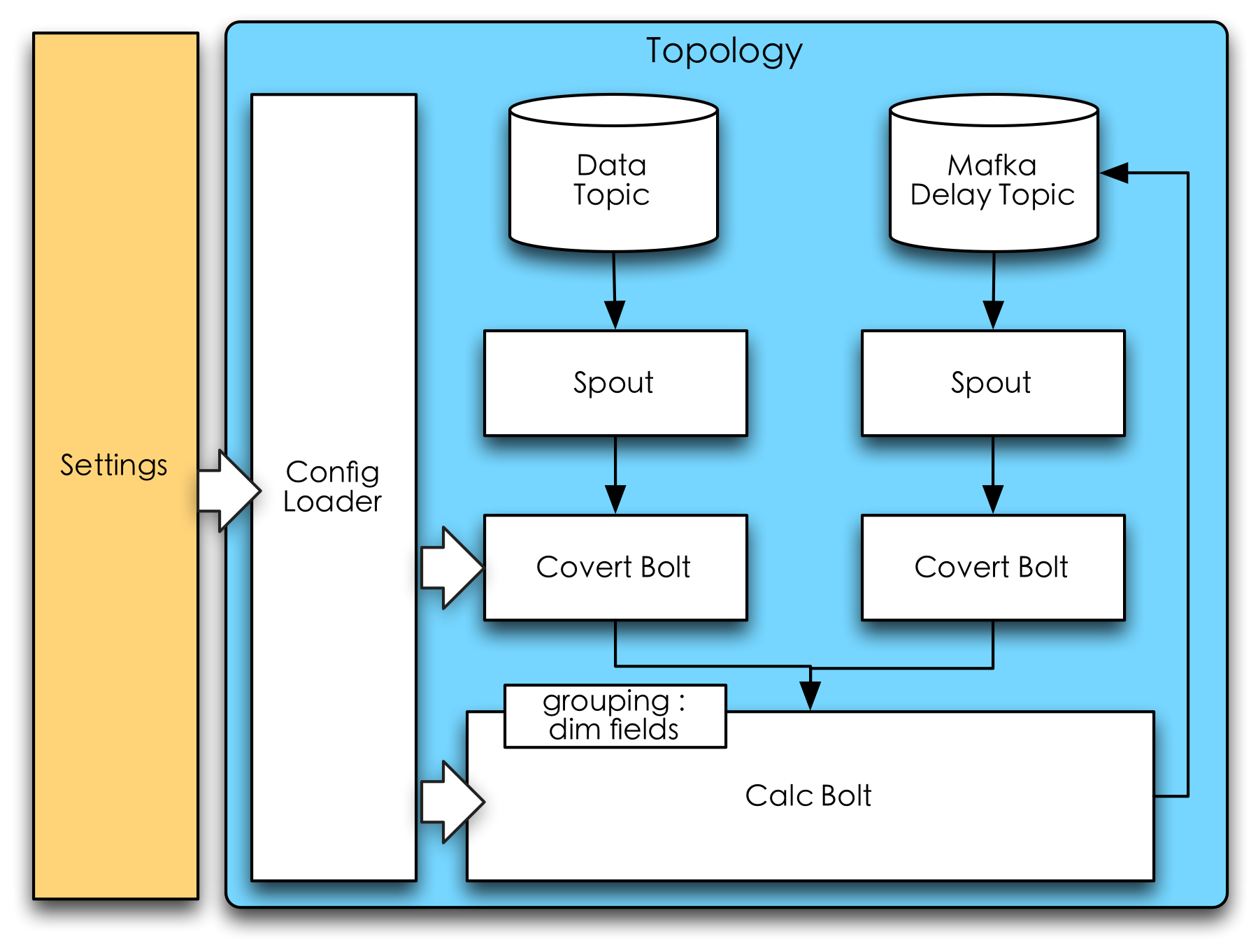
實時計算框架上述24個特征是常見的一些實時統計類特征,開發者只需要填寫表單,選擇需要的特征類型即可完成特征開發工作。對于現階段不支持配置實現的個性化、計算邏輯復雜的特征,開發者可以自己開發Storm拓撲實現計算邏輯(對應實時特征生產調度圖中灰色的Third Party模塊),并通過更新接口寫入到線上存儲引擎。
實時特征計算優化
從上述支持的特征列表中可以看出,實時計算框架目前只支持聚合、明細列表這樣的簡單特征。即便如此,實時特征計算還是面臨很大的挑戰。離線特征只需要計算出更新周期內特征的最終值即可,而實時特征需要把每次特征變化都要實時計算出來,它既要計算的快,又要計算的多,因此它無法支持很大量的數據。
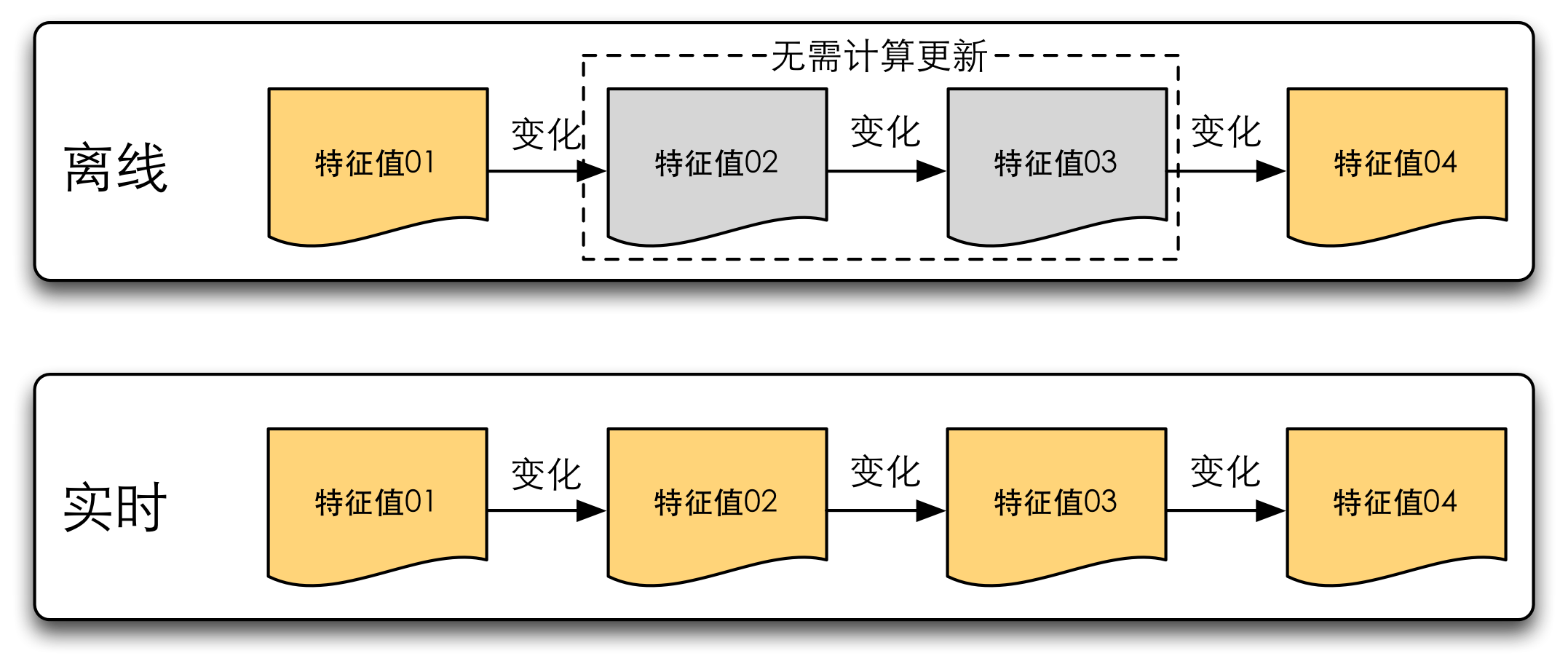
實時特征與離線特征對比當面臨數據計算量的挑戰時,優化思路之一是利用一些中間結果或上次計算結果簡化計算量,化全量計算為增量計算。例如求平均數這種特征,你可以存住所有的明細數據,當新的一條明細數據加入進來時,將所有明細數據求和再除以總數。這樣需要O(N)的時間和空間復雜度,N是明細數據個數。而你也可以僅保留總和跟總數,每次更新只要做一次加法和除法即可。
另一種優化思路是利用近似計算。比如求去重數(DISTINCT COUNT)這種指標,要精確計算可能很難找到一個時空復雜度都比較低的方案,而如果可以忍受近似計算的誤差,HyperLogLog算法是一個不錯的選擇。
在生產調度演進過程中,會不斷遇到各種系統問題,如可靠性、一致性、性能等等。在這一章節我們把特征生產調度中一些常見的技術手段,以及常見問題的解決方案匯總起來呈現給大家。
邏輯存儲層
邏輯存儲層的含義是Domain的元數據并不直接存放與存儲相關的信息,而是將這些信息抽象成Storage元數據,如下圖所示。其中Domain存儲了訪問控制、離線源信息、Storage ID等信息,而Storage則存儲了存儲介質、特征元數據、數據存儲格式等與存儲相關的信息。Domain與Storage是一對多的關系。
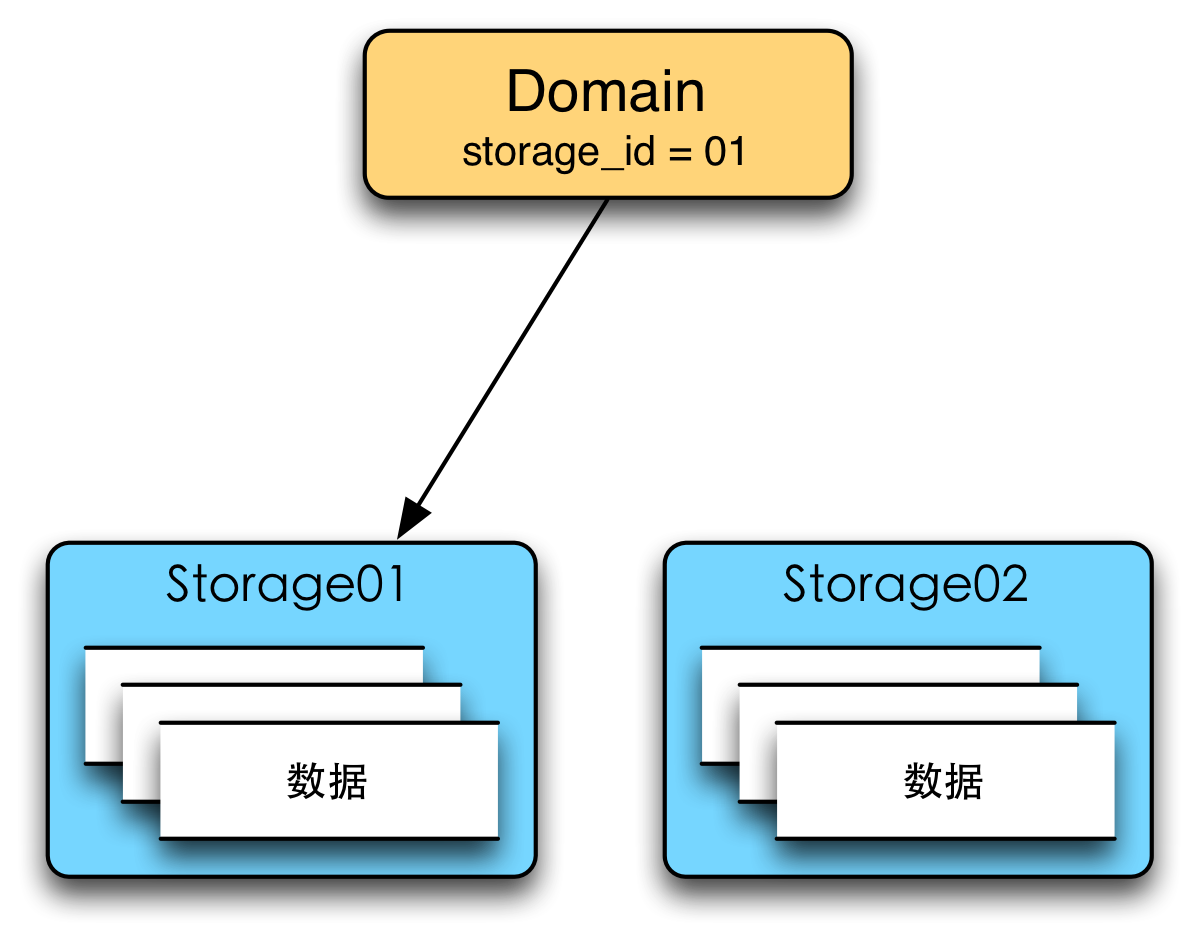
邏輯存儲層抽象存儲層Storage有很多好處:
增量更新與數據一致性
對于每日的離線特征更新,我們發現有些雖然總數據量龐大,但每天的變化比較少。比如用戶畫像,有很多沉睡的用戶他的特征基本不發生變化。如果每天將全量數據刷到線上,其實做了很多無謂的更新操作,對系統資源是一個巨大的浪費。尤其是更新線上存儲引擎,寫入壓力將導致在線服務穩定性的波動。因此考慮在更新前計算出特征的增量變化數據,只更新變化的部分。而計算增量數據需要有線上特征集合的完整離線數據備份——數據鏡像。
數據鏡像(SNAPSHOT)是對線上存儲引擎數據的離線備份。由于KV存儲的特點適用于隨機訪問,而對順序訪問(如遍歷)的支持并不是其強項,因此通過構造離線數據鏡像,可以一定程度上幫助我們更為方便的操作線上KV存儲引擎中的數據。這里主要是為了支持增量更新和數據恢復功能。
如下圖所示同一個更新周期(Period)內需要做兩次數據處理流程:歸檔(Archive)和同步(Sync)。Archive會將上一個更新周期的SNAPSHOT和這個更新周期的特征數據表做差集和并集。差集的結果是增量數據(Diff),并集的結果是該更新周期內的SNAPSHOT。對于數據量大而Diff又少的特征集合來說,增量更新會極大的節約線上的資源。
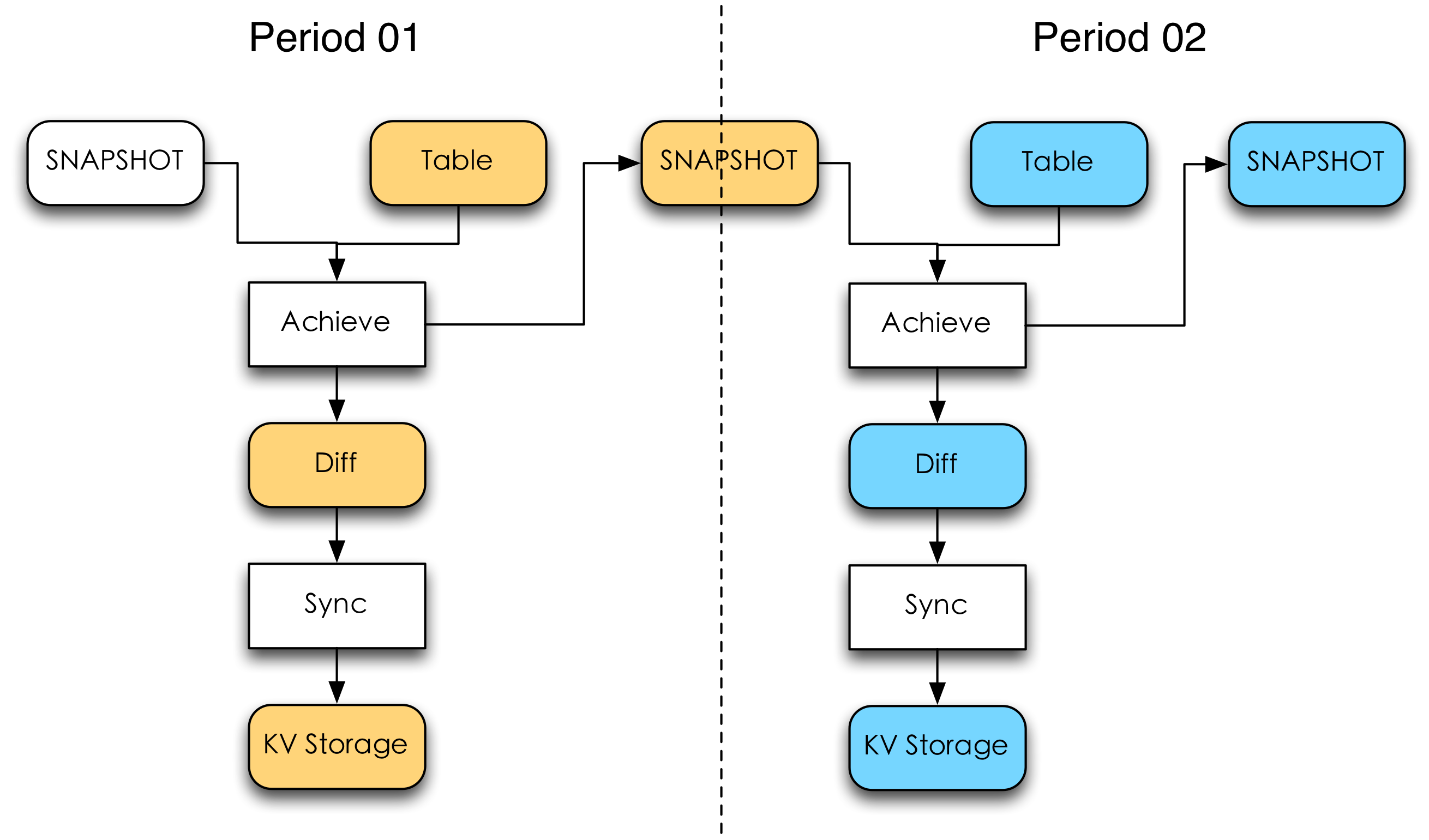
離線增量更新流程增量更新可能帶來數據一致性的問題。如果Sync步驟出現了少量數據更新失敗(比如寫操作偶然性超時),會導致SNAPSHOT與KV存儲引擎的數據不一致。這種問題在全量更新時并不是什么大問題,當數據在后續更新周期內全量寫入時,可以認為總會修復上次的更新失敗問題。然而在增量更新時,這種錯誤是永久性的。因此我們在生成SNAPSHOT時為每條數據附上一條租約(Lease),當租約到期時,強制將該條數據加入Diff參與當次更新,這樣可以保證數據的最終一致性。Lease的時間我們可以對每一條數據進行隨機分布,這樣需要更新的數據會平穩的分布到每一天而不出現明顯尖峰。Lease機制其實是全量更新到增量更新的一個平滑過渡,Lease為0時是全量更新,Lease為無窮大時是增量更新。
寫入削峰
隨著離線特征表增多,同一時刻進行數據導入的作業相互搶占資源,未加控制的寫入速度影響了KV存儲引擎的正常讀取,甚至引起雪崩。實時特征也面臨類似問題,實時數據流容易隨著集群的狀況、業務的特點出現流量峰谷,如果沒有消費速度的限制,很容易導致存儲引擎壓力突增突減,甚至將其打垮。
離線與實時通過不同手段控制并發寫入線上存儲速度。離線更新的特點是: 1. 更新具有周期性,需要同步時流量很大,同步結束后流量變為0 2. 對更新延遲性要求不高(往往在小時級別) 3. 寫入方完全是特征系統內部模塊(每個Sync作業)
我們的目標是盡快將這些數據同步到線上存儲引擎,同時兼顧寫入速度(影響更新延遲)和集群資源(線上存儲壓力)。鑒于離線更新的特點,且Sync作業本來就由調度器管理,因此很容易將并發控制實現在調度器內部。調度器會控制每個存儲引擎的最大Sync作業并發數量,同時每個Sync作業內部并發的寫入速度也是固定的。負載限制的關系如下:
同步中的作業數 * 作業內部并發度 ≤ 線上存儲引擎的最大寫入壓力
而實時特征更新的特點是: 1. 每時每刻都有寫入的流量 2. 流量隨著業務時間變化會有波動 3. 對更新延遲要求較高(往往在秒級) 4. 寫入方有特征系統內部模塊,也有第三方的服務
由于寫入方可能來自特征系統外部,難以統一控制寫入方速度,因此我們沒有像離線一樣讓寫入方直接操作線上存儲,而是在兩者之間增加了一個Updater服務(參考圖5.實時特征生產調度),由它控制每個寫入方的速度。實時特征流量波動大,且對更新延遲要求高,新接入的實時特征需要預估流量峰值并配置到Updater服務中。對于超過預設流量的請求予以拒絕或延遲。
原子更新
離線特征與實時特征面臨的原子更新問題各有不同。離線更新的粒度為天級別,所有特征一天只更新一次,有的特征集合希望保證天級別的更新是原子的。即不希望任意時刻出現一部分特征是昨天的值,一部分特征是今天的值。這個問題利用上文提到的邏輯存儲層可以很好的解決,這里不再贅述。
然而實時特征生產更新卻面臨另一種問題。很多時候需要先讀取特征當前值,然后基于當前值做計算得到新值寫入KV存儲引擎,一次更新過程涉及到讀取,計算、寫入三步。因此如果要保證數據更新的一致性,必須要保證一次更新的讀、算、寫操作的原子性或者事務性。對于原子更新的需求主要有兩類解決方案:
數據融合與數據恢復
如果說實時數據是離線數據的延伸,那么離線數據可以說是實時數據的備份,二者是相輔相成的。理論上,利用實時數據可以計算出所有想要的特征,但離線數據可以從不同方面解決實時特征計算中諸多棘手問題: - 提升效率。可以利用離線計算來提升效率。例如計算每個商家有史以來的營業額,如果全部采用實時數據,那將要實時回放歷史上所有訂單數據,這樣的數據量和計算代價都是巨大的,此時可以利用離線框架計算出歷史營業額,在特征初始化時將離線計算好的歷史營業額導入線上存儲引擎。之后的特征計算更新依賴實時框架,這樣可以節省系統開銷。 - 提升可靠性。可以利用離線計算和導入校正實時更新可能產生的誤差,提升數據可靠性。實時特征計算采用Storm框架,可以保證數據記錄不漏(At Least Once),但不能保證不重(At Most Once)。從系統設計的角度看,對于實時流式處理要做到確保計算一次(Exactly Once)的代價往往很高,相比于讓流式計算絕對可靠,與離線計算結果融合往往是更合適的選擇。對于像每日營業額這種固定時間窗的特征,實時更新流程只會更新當前時間窗內的特征(今日營業額),而并不會改動歷史時間窗的數據,因此歷史時間窗的特征可以利用離線數據重新校正一次,這樣可以保證數據的最終正確性。
離線實時特征生產整體架構上圖為離線實時特征生產的整體架構。離線與實時的數據融合,需要一個更強大的調度器,它負責協調離線任務與實時任務的關系,高效、可靠的完成數據導入工作。離線作業與實時作業的調度關系分為兩種: 1. 離線只初始化一次,后續只有實時數據從基于離線初始化的值做累積運算。如下圖的離線初始化。這種調度類型常見于無限時間窗口的一些計算指標,如商戶最后一次訂單時間,用戶累積消費金額等。 2. 離線與實時作業并存,離線作業定期復寫歷史數據,實時作業更新最近數據。如下圖的離線定期修復。這種調度類型常見于提升固定時間窗特征的可靠性,如商戶每日營業額等,這類特征在Key中攜帶時間信息,特征數據天然按時間窗分區,離線與實時作業更新不同分區的數據而互不影響。
離線初始化 離線定期修復數據恢復是指當線上數據發生問題的時候(可能由于數據源問題、線上故障、硬件故障等)如何修復線上數據,使其恢復到正常狀態。數據恢復是效率和可靠性的雙重考驗,越快速的恢復到正常狀態,系統的可靠性就越高。離線增量更新的特征與實時特征都是在原有特征基礎上累積計算,一旦某一時刻數據出現問題需要重導數據,只能從第一次增量開始重新累積,這無疑是及其低效的。如果能夠定期備份線上特征的數據鏡像,當實時更新從某一時刻出現故障時,可以用最近一次正確的離線SNAPSHOT版本刷新數據。離線數據最新的SNAPSHOT應與線上特征數據保持一致,而實時特征的SNAPSHOT會有一定延遲,這時只要將上游實時流數據回退到SNAPSHOT時間點重新開始消費(如下圖所示),這樣相比沒有SNAPSHOT可以較為快速的恢復故障。
數據恢復功能是離線與實時架構融合的產物,只不過它的離線數據不是業務上產出的某張離線表,而是離線鏡像數據SNAPSHOT。
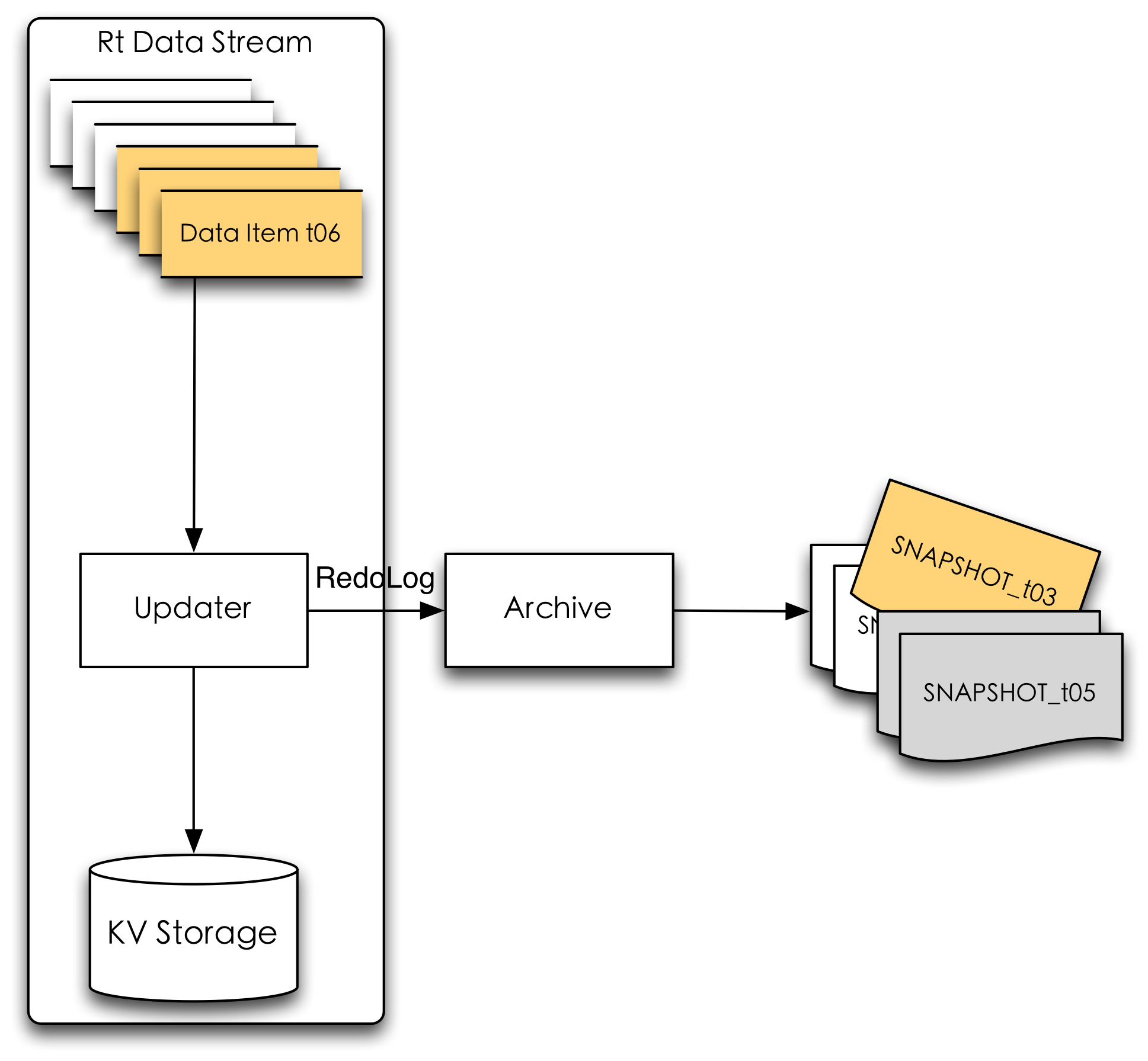
數據恢復一個完整的在線特征系統數據流涵蓋加載、計算、導入、存儲、讀取五個步驟。從兩類數據的五個步驟來看,在線特征系統截至目前還并不完整;而深入到每一個步驟,還有很多功能特性需要繼續完善:支持離線計算框架、支持更多的實時計算類型、實時特征計算高可用、縮短數據恢復時間、特征實時監控等等。在與其他團隊交流時,也有將特征系統深入到策略系統內部,實現算法、特征迭代一體化流程。在線特征系統的工作仍任重而道遠。
能力所限,難免管中窺豹,掛一漏萬。歡迎感興趣同學一起交流。
楊浩,美團平臺及酒旅事業群數據挖掘系統負責人,2011年畢業于北京大學,曾擔任107間聯合創始人兼CTO,2016年加入美團點評。長期致力于計算廣告、搜索推薦、數據挖掘等系統架構方向。
偉彬,美團平臺及酒旅事業群數據挖掘系統工程師,2015年畢業于大連理工大學,同年加入美團點評,專注于大數據處理技術與高并發服務。
最后發個廣告,美團平臺及酒旅事業群數據挖掘組長期招聘數據挖掘算法、大數據系統開發、Java后臺開發方面的人才,有興趣的同學可以發送簡歷到yanghao13#meituan.com。
總結
以上是生活随笔為你收集整理的人工智能在线特征系统中的生产调度的全部內容,希望文章能夠幫你解決所遇到的問題。

- 上一篇: 最强阿里面试126题:数据结构+并发编程
- 下一篇: 阿里Java架构师精通资料:性能优化+亿