动漫之家《妖神记》爬虫(2021-01-09)
生活随笔
收集整理的這篇文章主要介紹了
动漫之家《妖神记》爬虫(2021-01-09)
小編覺得挺不錯的,現在分享給大家,幫大家做個參考.
動漫之家《妖神記》爬蟲
目標:動漫之家《妖神記》爬蟲,聽課習作
目標網址:https://www.dmzj.com/info/yaoshenji.html
主要知識
——自動判斷、創建所需目錄
——切片知識
——bs4解析庫使用技巧
——網址拼接技巧
——初級防爬Referer
——爬取結果反向排序
——圖片文件保存
——正則使用
——html.script
程序中有詳細步驟、解釋
```python ''' -*- coding: utf-8 -*- @Author : hshcompass @QQ : 46215528 @Time : 2021/1/9 14:38 @Software: PyCharm @File : 妖神記.py ''' # 爬取動漫之家----Yaoshenji# 導入庫 import re, os, time, requests from bs4 import BeautifulSoup# 保存目錄 save_dir = '妖神記' if save_dir not in os.listdir('./'):os.mkdir(save_dir)# 1 獲取所有章節名稱和章節鏈接# 目標網址 url ='https://www.dmzj.com/info/yaoshenji.html'# 發送請求,獲取響應 response =requests.get(url)# 提取數據,解析網頁 soup = BeautifulSoup(response.text, 'lxml')# 圖片位于 ul 標簽 下的 li 標簽,具體鏈接是 a 標簽 list_con_li = soup.find('ul', class_="list_con_li autoHeight") cartoon_list = list_con_li.find_all('a')# 章節名稱、鏈接 charpter_names = [] charpter_urls = []for cartoon in cartoon_list:href = cartoon.get('href')name = cartoon.textcharpter_names.insert(0,name) # 沒有使用 append 是因為章節是倒序排列,所以用 insertcharpter_urls.insert(0,href)# 2 根據每個章節鏈接獲取所有圖片鏈接 for i, url in enumerate(charpter_urls):"""返回章節目錄列表的索引位置"""name = charpter_names[i]# 為每一章節創建目錄# 避免創建文件夾報錯 把 . 去掉while '.' in name:name = name.replace('.', '')# 創建章節目錄charpter_save_dir = os.path.join(save_dir, name)if name not in os.listdir(save_dir):os.mkdir(charpter_save_dir)response = requests.get(url)html = BeautifulSoup(response.text, 'lxml')# 獲取script 標簽里的內容script_info = html.script# 找長度為 13 或 14 的數字,取出來并 轉為 str 字符串pics = re.findall('\|(\d{13,14})\|', str(script_info))# print(pics)# 遍歷取出來的數字for j, pic in enumerate(pics):# 有的是 13 有的是 14 ,對 13 位的數字末位補 0if len(pics) == 13:pics[j] = pic + '0'# 圖片排序pics = sorted(pics, key=lambda x:int(x))charpter_hou = re.findall('\|(\d{5})\|', str(script_info))[0]charpter_qian = re.findall('\|(\d{4})\|', str(script_info))[0]headers = {'Referer': url, # 初級反爬'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}# 拼接鏈接網址for idx, pic in enumerate(pics):# 如果最后一位數字是 0if pic[:-1] == '0':# 【:-1】 表示切片時不要最后一位,取到最后一位前面url = 'https://images.dmzj.com/img/chapterpic/' + charpter_qian + '/' + charpter_hou + '/' + pic[:-1] + '.jpg'else:url = 'https://images.dmzj.com/img/chapterpic/' + charpter_qian + '/' + charpter_hou + '/' + pic + '.jpg'print(url)# 保存圖片名和圖片保存圖片路徑pic_name = '%03d.jpg' %(idx +1) # 001-002-003.....199 避免圖片數量超過設置,擴大一些pic_save_path = os.path.join(charpter_save_dir, pic_name)# 發送請求,下載圖片resp = requests.get(url, headers = headers)# 如果狀態碼 正常 200,保存圖片文件if resp.status_code == 200:with open(pic_save_path, 'wb') as f:f.write(resp.content)else:print('鏈接異常') 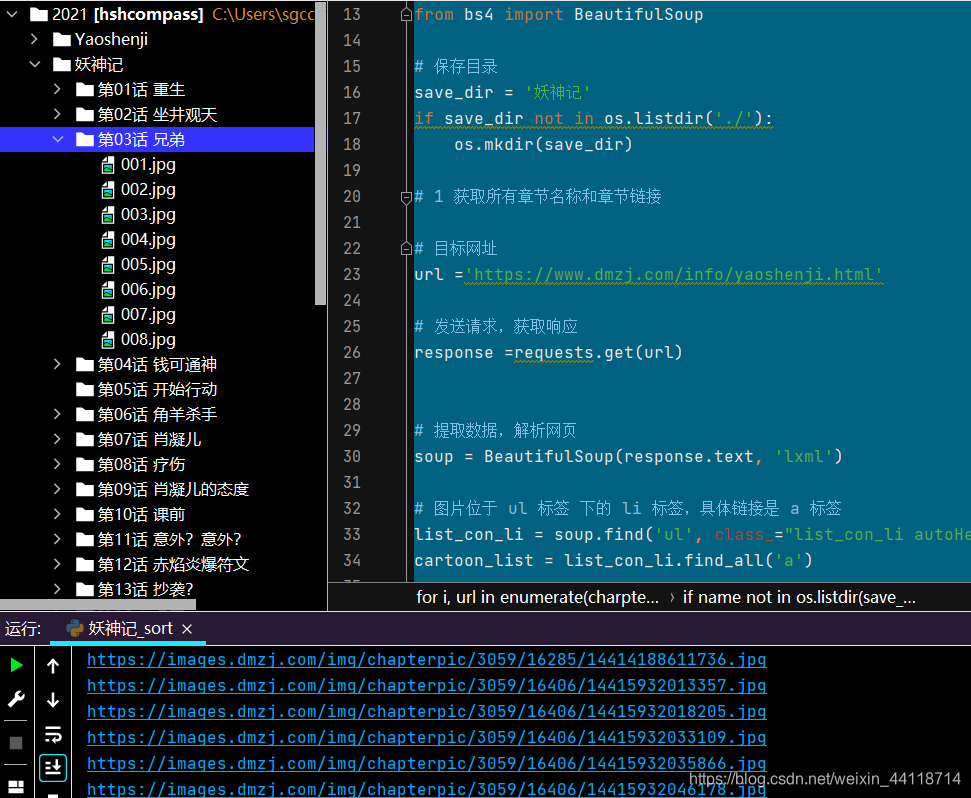總結
以上是生活随笔為你收集整理的动漫之家《妖神记》爬虫(2021-01-09)的全部內容,希望文章能夠幫你解決所遇到的問題。

- 上一篇: 浙江大学 计算机学院 刘辉,【夏文莉】_
- 下一篇: pascal行人voc_在一个很小的Pa