Java基础知识1-10
測試要點
- 一、Java基礎
- 1.常用設計模式有哪些?在項目中有哪里用的到?單例中懶漢餓漢優缺點?
- 軟件設計模式分為三類分別為創建型、結構型、行為型。
- 1.1創建型
- 1.1.1單例模式(singleton)
- 1.1.2 簡單工廠(StaticFactory Method)
- 1.1.3 工廠方法(Factory Method)和抽象工廠(Abstract Factory)
- 1.2、結構模式
- 1.2.1代理模式(Proxy)
- 1.2.2 享元模式
- 1.2.3 裝飾器模式
- 1.2.4 適配器模式
- 1.3、行為型
- 1.3.1 命令模式(Command)
- 1.3.2 策略模式(Strategy)
- 1.3.3 觀察者模式(Observer)
- 2.反射的原理?獲取class對象的方式有哪些? 如何用反射取私有屬性filed?
- 2.1 反射的原理
- 2.2 獲取class對象的方式有哪些
- 2.3 如何用反射取私有屬性filed
- 3.jvm垃圾回收機制和jvm調優?
- 3.1 jvm垃圾回收機制
- 3.2 jvm調優
- 4.線程的創建、開啟、狀態、狀態切換?sleep和wait的區別?如何保證線程安全?為什么使用多線程?線程池的了解?
- 4.1 創建
- 4.2 開啟 thread.start();
- 4.3 狀態和狀態切換
- 新建狀態(new)
- 當一個線程對象啟動了start()方法后,該線程就處于就緒狀態,
- 如果一個線程處于這個狀態,那么它正在占用CPU,執行程序代碼.只有處于就緒狀態的線程才有機會轉到運行狀態.
- 死亡狀態(Dead)
- sleep和wait的區別
- 區別:
- 4.4 如何保證線程安全
- 4.5 為什么使用多線程
- 4.6 線程池
- 概念
- 功能
- 5.集合有哪些?哪些是線程安全的集合?hashmap的底層原理?hashMap、hashTable、currenthashmap區別?ArrayList、vector、linkedlist的區別?
- 5.1 List、Set、Map三類集合
- 1、list集合
- ArrayList集合
- LinkedList集合
- Vector集合
- 2、Set集合
- Hashset:
- LinkedHashset:
- Treeset:
- 3、Map集合
- HashMap:
- TreeSet:
- LInkedHashMap:
- 5.2 線程安全的集合
- 5.3 hashMap的底層原理
- 5.4 hashMap和hashTable、currenthashMap區別
- 5.5 ArrayList、vector、LinkedList的區別
- 5.5.1 從存儲數據結構分析
- 5.5.2 從繼承上分析
- 5.5.3 從并發安全上分析
- 5.5.4 數據增長分析
- 6.jvm內存模型的理解?
- 6.1 方法區(Method Area)
- 6.2 堆(Heap)
- 6.3 虛擬機棧(Java Stack)
- 6.4 本地方法棧(Native Method Stack)
- 6.5 程序計數器(Program Counter Register)
- 7 抽象類與接口的區別?
- 7.1 接口
- 7.2 抽象類
- 區別
- 8 volatile與synchronized的區別?
- 8.1
- 8.2
- 8.3
- 8.4
- 8.5
- 9 重寫與重載的區別?
- 10 java中字符串的方法有哪些?string、stringbuffer和stringbuilder的區別?
- 10.1 java中字符串的方法有哪些?
- 10.2string、stringbuffer和stringbuilder的區別?
一、Java基礎
1.常用設計模式有哪些?在項目中有哪里用的到?單例中懶漢餓漢優缺點?
軟件設計模式分為三類分別為創建型、結構型、行為型。
1.1創建型
創建對象時,不再由我們直接實例化對象;而是根據特定場景,由程序來確定創建對象的方式,從而保證更大的性能、更好的架構優勢。創建型模式主要有簡單工廠模式(并不是23種設計模式之一)、工廠方法、抽象工廠模式、單例模式、生成器模式和原型模式。
1.1.1單例模式(singleton)
有些時候,允許自由創建某個類的實例沒有意義,還可能造成系統性能下降。如果一個類始終只能創建一個實例,則這個類被稱為單例類,這種模式就被稱為單例模式一般建議單例模式的方法命名為:getInstance(),這個方法的返回類型肯定是單例類的類型了。getInstance方法可以有參數,這些參數可能是創建類實例所需要的參數,當然,大多數情況下是不需要的
public class Singleton {
public static void main(String[] args)
{
//創建Singleton對象不能通過構造器,只能通過getInstance方法
Singleton s1 = Singleton.getInstance();
Singleton s2 = Singleton.getInstance();
//將輸出true
System.out.println(s1 == s2);
} private static Singleton instance;
//將構造器使用private修飾,隱藏該構造器
private Singleton(){
System.out.println("Singleton被構造!");
}
//提供一個靜態方法,用于返回Singleton實例
//該方法可以加入自定義的控制,保證只產生一個Singleton對象
public static Singleton getInstance()
{
//如果instance為null,表明還不曾創建Singleton對象
//如果instance不為null,則表明已經創建了Singleton對象,將不會執行該方法
if (instance == null)
{
//創建一個Singleton對象,并將其緩存起來
instance = new Singleton();
}
returninstance;
}
}
(1)、懶漢式(上面的就是懶漢式寫法)
public class Singleton {
private static Singleton instance;
private Singleton (){}
public static synchronized Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
(2)、餓漢式
public class Singleton {
private static Singleton instance = new Singleton();
private Singleton (){}
public static Singleton getInstance() {
return instance;
}
}
懶漢式和餓漢式的優缺點
1、餓漢式是線程安全的,在類創建的同時就已經創建好一個靜態的對象供系統使用,以后不在改變。懶漢式如果在創建實例對象時不加上synchronized則會導致對對象的訪問不是線程安全的。
2、懶漢式是典型的時間換空間,也就是每次獲取實例都會進行判斷,看是否需要創建實例,浪費判斷的時間。當然,如果一直沒有人使用的話,那就不會創建實例,則節約內存空間。
餓漢式是典型的空間換時間,當類裝載的時候就會創建類實例,不管你用不用,先創建出來,然后每次調用的時候,就不需要再判斷了,節省了運行時間。
單例模式主要有如下兩個優勢:
減少創建Java實例所帶來的系統開銷
便于系統跟蹤單個Java實例的生命周期、實例狀態等。
1.1.2 簡單工廠(StaticFactory Method)
簡單工廠模式是由一個工廠對象決定創建出哪一種產品類的實例。簡單工廠模式是工廠模式家族中最簡單實用的模式,可以理解為是不同工廠模式的一個特殊實現。
A實例調用B實例的方法,稱為A依賴于B。如果使用new關鍵字來創建一個B實例(硬編碼耦合),然后調用B實例的方法。一旦系統需要重構:需要使用C類來代替B類時,程序不得不改寫A類代碼。而用工廠模式則不需要關心B對象的實現、創建過程
使用簡單工廠模式的優勢:讓對象的調用者和對象創建過程分離,當對象調用者需要對象時,直接向工廠請求即可。從而避免了對象的調用者與對象的實現類以硬編碼方式耦合,以提高系統的可維護性、可擴展性。工廠模式也有一個小小的缺陷:當產品修改時,工廠類也要做相應的修改。
1.1.3 工廠方法(Factory Method)和抽象工廠(Abstract Factory)
如果我們不想在工廠類中進行邏輯判斷,程序可以為不同產品類提供不同的工廠,不同的工廠類和產不同的產品。
當使用工廠方法設計模式時,對象調用者需要與具體的工廠類耦合使用簡單工廠類,需要在工廠類里做邏輯判斷。而工廠類雖然不用在工廠類做判斷。但是帶來了另一種耦合:客戶端代碼與不同的工廠類耦合。
為了解決客戶端代碼與不同工廠類耦合的問題。在工廠類的基礎上再增加一個工廠類,該工廠類不制造具體的被調用對象,而是制造不同工廠對象
1.2、結構模式
用于幫助將多個對象組織成更大的結構。結構型模式主要有適配器模式adapter、橋接模式bridge、組合器模式component、裝飾器模式decorator、門面模式、亨元模式flyweight和代理模式proxy。
1.2.1代理模式(Proxy)
代理模式是一種應用非常廣泛的設計模式,當客戶端代碼需要調用某個對象時,客戶端實際上不關心是否準確得到該對象,它只要一個能提供該功能的對象即可,此時我們就可返回該對象的代理(Proxy)
1.2.2 享元模式
應用:在一個系統中,如果有多個相同的對象,那么只共享一份就ok了。不必每個都去實例化一個對象,可以節省大量的內存空間。
在Java中,String類型的使用了享元模式,String對象是final類型的,對象一旦創建就不可以被改變。在Java中字符串常量都是存在常量池中的,Java會確保一個字符串常量在常量池中只有一個拷貝。
1.2.3 裝飾器模式
對已有的業務邏輯進一步的封裝,使其增加額外的功能,如Java中的IO流就使用了裝飾者模式,用戶在使用的時候,可以任意組裝,達到自己想要的效果。
1.2.4 適配器模式
將兩種完全不同的事物聯系到一起,就像現實生活中的變壓器。假設一個手機充電器需要的電壓是20V,但是正常的電壓是220V,這時候就需要一個變壓器,將220V的電壓轉換成20V的電壓,這樣,變壓器就將20V的電壓和手機聯系起來了。
1.3、行為型
用于幫助系統間各對象的通信,以及如何控制復雜系統中流程。行為型模式主要有命令模式command、解釋器模式、迭代器模式、中介者模式、備忘錄模式、觀察者模式、狀態模式state、策略模式、模板模式和訪問者模式。
1.3.1 命令模式(Command)
某個方法需要完成某一個功能,完成這個功能的大部分步驟已經確定了,但可能有少量具體步驟無法確定,必須等到執行該方法時才可以確定。(在某些編程語言如Ruby、Perl里,允許傳入一個代碼塊作為參數。但Jara暫時還不支持代碼塊作為參數)。在Java中,傳入該方法的是一個對象,該對象通常是某個接口的匿名實現類的實例,該接口通常被稱為命令接口,這種設計方式也被稱為命令模式。
1.3.2 策略模式(Strategy)
策略模式用于封裝系列的算法,這些算法通常被封裝在一個被稱為Context的類中,客戶端程序可以自由選擇其中一種算法,或讓Context為客戶端選擇一種最佳算法——使用策略模式的優勢是為了支持算法的自由切換。
DiscountStrategy,折扣方法接口
public interface DiscountStrategy
{
//定義一個用于計算打折價的方法
double getDiscount(double originPrice);
}
OldDiscount,舊書打折算法
public class OldDiscount implements DiscountStrategy {
// 重寫getDiscount()方法,提供舊書打折算法
publicdouble getDiscount(double originPrice) {
System.out.println("使用舊書折扣...");
return originPrice * 0.7;
}
}
VipDiscount,VIP打折算法
//實現DiscountStrategy接口,實現對VIP打折的算法
public class VipDiscount implements DiscountStrategy {
// 重寫getDiscount()方法,提供VIP打折算法
publicdouble getDiscount(double originPrice) {
System.out.println("使用VIP折扣...");
return originPrice * 0.5;
}
}
策略定義
public static void main(String[] args)
{
//客戶端沒有選擇打折策略類
DiscountContext dc = new DiscountContext(null);
double price1 = 79;
//使用默認的打折策略
System.out.println("79元的書默認打折后的價格是:"
+ dc.getDiscountPrice(price1));
//客戶端選擇合適的VIP打折策略
dc.setDiscount(new VipDiscount());
double price2 = 89;
//使用VIP打折得到打折價格
System.out.println("89元的書對VIP用戶的價格是:"
+ dc.getDiscountPrice(price2));
}
測試
publicstaticvoid main(String[] args)
{
//客戶端沒有選擇打折策略類
DiscountContext dc = new DiscountContext(null);
double price1 = 79;
//使用默認的打折策略
System.out.println("79元的書默認打折后的價格是:"
+ dc.getDiscountPrice(price1));
//客戶端選擇合適的VIP打折策略
dc.setDiscount(new VipDiscount());
double price2 = 89;
//使用VIP打折得到打折價格
System.out.println("89元的書對VIP用戶的價格是:"
+ dc.getDiscountPrice(price2));
}
使用策略模式可以讓客戶端代碼在不同的打折策略之間切換,但也有一個小小的遺憾:客戶端代碼需要和不同的策略耦合。為了彌補這個不足,我們可以考慮使用配置文件來指定DiscountContext使用哪種打折策略——這就徹底分離客戶端代碼和具體打折策略類。
1.3.3 觀察者模式(Observer)
觀察者模式定義了對象間的一對多依賴關系,讓一個或多個觀察者對象觀察一個主題對象。當主題對象的狀態發生變化時,系統能通知所有的依賴于此對象的觀察者對象,從而使得觀察者對象能夠自動更新。
在觀察者模式中,被觀察的對象常常也被稱為目標或主題(Subject),依賴的對象被稱為觀察者(Observer)。
主題中有觀察者對象組成的集合。
2.反射的原理?獲取class對象的方式有哪些? 如何用反射取私有屬性filed?
2.1 反射的原理
『反射』就是指程序在運行時能夠動態的獲取到一個類的類型信息的一種操作。它是現代框架的靈魂,幾盡所有的框架能夠提供的一些自動化機制都是靠反射實現的,這也是為什么各類框架都不允許你覆蓋掉默認的無參構造器的原因,因為框架需要以反射機制利用無參構造器創建實例。
Java反射就是在運行狀態中,對于任意一個類,都能夠知道這個類的所有屬性和方法;對于任意一個對象,都能夠調用它的任意方法和屬性;并且能改變它的屬性。總結說:反射就是把java類中的各種成分映射成一個個的Java對象,并且可以進行操作。
2.2 獲取class對象的方式有哪些
1.對象調用 getClass() 方法來獲取,通常應用在:比如你傳過來一個 Object
類型的對象,而我不知道你具體是什么類,用這種方法
Person p1 = new Person();
Class c1 = p1.getClass();
2.類名.class 的方式得到,該方法最為安全可靠,程序性能更高
這說明任何一個類都有一個隱含的靜態成員變量 class
Class c2 = Person.class;
3.通過 Class 對象的 forName() 靜態方法來獲取,用的最多,
但可能拋出 ClassNotFoundException 異常
Class c3 = Class.forName(“reflex.Person”);
2.3 如何用反射取私有屬性filed
public static void main(String[] args) throws NoSuchFieldException {
// TODO Auto-generated method stub
/*
* 使用反射來創建構造方法私有化的對象
* */
//1:獲取類的無參構造方法
Test test = new Test("張三");
Method[] methods = Test.class.getMethods();
Field[] fields = Test.class.getDeclaredFields();
for (int i = 0; i < fields.length; i++) {
fields[i].setAccessible(true);
try {
System.out.println(fields[i].get(test));
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalAccessException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(fields[i].getName());
}
}
然后,我們再來看一下輸出的:
張三
name
0
age
3.jvm垃圾回收機制和jvm調優?
3.1 jvm垃圾回收機制
垃圾回收(Garbage Collection)是Java虛擬機(JVM)垃圾回收器提供的一種用于在空閑時間不定時回收無任何對象引用的對象占據的內存空間的一種機制。
垃圾回收回收的是無任何引用的對象占據的內存空間而不是對象本身。換言之,垃圾回收只會負責釋放那些對象占有的內存。對象是個抽象的詞,包括引用和其占據的內存空間。當對象沒有任何引用時其占據的內存空間隨即被收回備用,此時對象也就被銷毀。但不能說是回收對象,可以理解為一種文字游戲
3.2 jvm調優
參考
1.GC優化流程
GC頻率不高,GC耗時不高,那么沒有必要進行GC優化;如果GC時間超過1-3秒,或者頻繁GC,則必須優化。指標參考:
a.Minor GC執行時間不到50ms;
b.Minor GC執行不頻繁,約10秒一次;
c.Full GC執行時間不到1s;
d.Full GC執行頻率不算頻繁,不低于10分鐘1次
1、性能定義:
①內存占用:垃圾收集器流暢運行所需要的內存數量。
②延遲:其度量標準是縮短由于垃圾啊收集引起的停頓時間或者完全消除因垃圾收集所引起的停頓,避免應用運行時發生抖動。
③吞吐量:指單位時間內系統處理用戶的請求數。此處需要滿足不考慮垃圾收集引起的停頓時間或內存消耗,能支撐應用達到的最高性能指標。
這三個屬性中,其中一個任何一個屬性性能的提高,幾乎都是以另外一個或者兩個屬性性能的損失作代價,不可兼得,具體某一個屬性或者兩個屬性的性能對應用來說比較重要,要基于應用的業務需求來確定。另外調優一般是從滿足程序的內存使用需求開始的,之后是時間延遲的要求,最后才是吞吐量的要求,要基于這個步驟來不斷優化,每一個步驟都是進行下一步的基礎,不可逆行之。
2、調優過程中的原則
a.每次minor GC都要盡可能多的收集垃圾對象,以減少應用程序發生Full GC的頻率。將轉移到老年代的對象數量降低到最小,減少Major GC/Full GC的執行時間。解決方法如下:
①調整新生代的大小到最合適;
②選擇合適的GC收集器;
③設置老年代的大小為最合適;
④減少使用全局變量和大對象;
b.GC內存最大化原則:處理吞吐量和延遲問題時候,垃圾處理器能使用的內存越大,垃圾收集的效果越好,應用程序也會越來越流暢。
c.在性能屬性里面,吞吐量、延遲、內存占用,我們只能選擇其中兩個進行調優,不可三者兼得。
2.內存調優
1.測試時,啟動參數采用JVM默認參數,不人為設置。
2.確保Full GC發生時,應用程序正處于穩定階段。
3.延遲調優
在確定了應用程序的內存調優數據大小之后,我們需要再進行延遲性調優,因為對于此時堆內存大小,延遲性需求無法達到應用的需要,需要基于應用的情況來進行調試。這一步進行期間,我們可能會再次優化堆大小的配置,評估GC的持續時間和頻率、以及是否需要切換到不同的垃圾收集器上。
4.吞吐量調優
吞吐量調優主要是基于應用程序的吞吐量(例如每小時批處理系統能完成的任務數量,在吞吐量方面優化的系統,較長的 GC 停頓時間也是可以接受的)要求而來的,應用程序有一個綜合的吞吐指標,這個指標基于整個應用的需求和測試而衍生出來的。當有應用程序的吞吐量達到或者超過預期的吞吐目標,整個調優過程就可以圓滿結束了。如果出現調優后依然無法達到應用程序的吞吐目標,需要重新回顧吞吐要求,評估當前吞吐量和目標差距是否巨大,如果在20%左右,可以修改參數,加大內存,再次從頭調試,如果巨大就需要從整個應用層面來考慮,設計以及目標是否一致了,重新評估吞吐目標。
對于JVM調優來說,提升吞吐量的性能調優的目標就是就是盡可能避免或者很少發生FullGC 或者Stop-The-World壓縮式垃圾收集(CMS),因為這兩種方式都會造成應用程序吞吐量降低。盡量在Minor GC階段回收更多的對象,避免對象提升過快到老年代
4.線程的創建、開啟、狀態、狀態切換?sleep和wait的區別?如何保證線程安全?為什么使用多線程?線程池的了解?
4.1 創建
方式一:定義一個類繼承Thread重寫run方法,把線程要運行的代碼寫入run方法中創建Thread子類對象,調用start方法
方式二:定義一個類實現Runnable接口重寫run方法 創建Thread類對象,創建Runnable實現類對象作為次數傳入到Thread類的構造方法里面調用Thread類對象的start方法開啟一個線程
4.2 開啟 thread.start();
4.3 狀態和狀態切換
新建狀態(new)
用new語句創建的線程處于新建狀態,此時它和其他Java對象一樣,僅僅在堆區中被分配了內存.它會一直保持這個狀態直到啟動了start()方法.
就緒狀態(Runnable)
當一個線程對象啟動了start()方法后,該線程就處于就緒狀態,
Java虛擬機會為它創建方法調用棧和程序計數器.處于這個狀態的線程位于可運行池中,等待獲得CPU的使用權.
運行狀態(Running)
如果一個線程處于這個狀態,那么它正在占用CPU,執行程序代碼.只有處于就緒狀態的線程才有機會轉到運行狀態.
阻塞狀態(Blocked)
阻塞狀態是指線程因為某些原因放棄CPU,暫時停止運行.當線程處于阻塞狀態時,java虛擬機不會給線程分配CPU。直到線程重新進入就緒狀態,它才有機會轉到運行狀態.
阻塞狀態可分為三種:
1.位于對象等待池中(in Object’s wait pool)當線程處于運行狀態的時候,如果執行了某個對象的wait()方法,java虛擬機就會把這個線程放到這個對象的等待池中.這設計到線程通信的內容.
2.位于對象鎖池中(in Object’s lock pool)當線程處于運行狀態時,試圖獲得某個對象的同步鎖時,如果該對象的同步鎖已經被其他線程占用,java虛擬機就會把這個線程放到這個對象從鎖池中,這涉及到"線程同步"的內容
3.其他阻塞狀態(otherwise Blocked)當前線程執行了sleep()方法,或者調用了其他線程的join()方法,或者發出了I/O請求時,就會進入這個狀態.
死亡狀態(Dead)
當線程退出run()方法時,就進入死亡狀態,該線程結束生命周期
sleep和wait的區別
sleep的作用是讓線程休眠指定的時間,在時間到達時恢復,也就是說sleep將在接到時間到達事件事恢復線程執行。
調用wait方法將會將調用者的線程掛起,直到其他線程調用同一個對象的notify方法才會重新激活調用者。
區別:
1、來自不同的類:sleep是Thread的靜態類方法,誰調用的誰去睡覺,即使在a線程里調用了b的sleep方法,實際上還是a去睡覺,要讓b線程睡覺要在b的代碼中調用sleep。
2、有沒有釋放鎖(釋放資源):sleep不讓出系統資源;wait是進入線程等待池等待,讓出系統資源,其他線程可以占用CPU。
3、一般wait不會加時間限制,因為如果wait線程的運行資源不夠,再出來也沒用,要等待其他線程調用notify/notifyAll喚醒等待池中的所有線程,才會進入就緒隊列等待OS分配系統資源。sleep(milliseconds)可以用時間指定使它自動喚醒過來,如果時間不到只能調用interrupt()強行打斷。
4、sleep必須捕獲異常,而wait,notify和notifyAll不需要捕獲異常。
4.4 如何保證線程安全
1、互斥同步
互斥同步是最常見的一種并發正確性保障手段。同步是指在多線程并發訪問共享數據時,保證共享數據在同一時刻只被一個線程使用(同一時刻,只有一個線程在操作共享數據)。而互斥是實現同步的一種手段,臨界區、互斥量和信號量都是主要的互斥實現方式。因此,在這4個字里面,互斥是因,同步是果; …
2、非阻塞同步
隨著硬件指令集的發展,出現了基于沖突檢測的樂觀并發策略,通俗地說,就是先進行操作,如果沒有其他線程爭用共享數據,那操作就成功了;如果共享數據有爭用,產生了沖突,那就再采用其他的補償措施。(最常見的補償錯誤就是不斷地重試,直到成功為止),這種樂觀的并發策略的許多實現都不需要 …
3、無需同步方案
要保證線程安全,并不是一定就要進行同步,兩者沒有因果關系。同步只是保證共享數據爭用時的正確性的手段,如果一個方法本來就不涉及共享數據,那它自然就無需任何同步操作去保證正確性,因此會有一些代碼天生就是線程安全的。
4.5 為什么使用多線程
- 提高應用程序響應。這對圖形界面的程序尤其有意義,當一個操作耗時很長時,整個系統都會等待這個操作,此時程序不會響應鍵盤、鼠標、菜單的操作,而使用多線程技術,將耗時長的操作(time consuming)置于一個新的線程,可以避免這種尷尬的情況。
- 使多CPU系統更加有效。操作系統會保證當線程數不大于CPU數目時,不同的線程運行于不同的CPU上。
- 改善程序結構。一個既長又復雜的進程可以考慮分為多個線程,成為幾個獨立或半獨立的運行部分,這樣的程序會利于理解和修改。
4.6 線程池
概念
所謂線程池,就是一個用來放線程的池子,里面存放著已經創建好的線程,當有任務提交的時候,池子里面的某個線程會執行這個任務,當任務結束后,線程又回到了池子里面等待下一個任務。當任務太多的時候,池子就要自動加水,創建更多的線程,但池子也是有容量的;當任務太少的時候,池子就要放掉一些線程,以免資源浪費。
功能
任務隊列:用于緩存已經提交的任務。
線程數量管理:線程池應該自動控制線程池里面線程的數量,可以通過以下三個參數來實現:(1)初始線程數init,線程池能容納最大線程數max,線程的活躍數量:core,三者的關系是int<=core<=max
任務拒絕策略:當線程數量達到上限且任務隊列滿的時候,需要有對應的拒絕策略來通知提交者線程被拒絕。
線程工廠:用于自定義線程,比如設置線程名稱等。
提交隊列:用于存放提交的線程,需要有數量限制。
活躍時間:線程自動維護的時間。
5.集合有哪些?哪些是線程安全的集合?hashmap的底層原理?hashMap、hashTable、currenthashmap區別?ArrayList、vector、linkedlist的區別?
5.1 List、Set、Map三類集合
1、list集合
ArrayList集合
底層數據結構是數組,查詢快,增刪慢,查詢是根據數組下標直接查詢速度快,增刪需要移動后邊的元素和擴容,速度慢。線程不安全,效率高
LinkedList集合
底層數據結構是鏈表,查詢慢,增刪快,查詢需要遍歷數組,速度慢,增刪只需要增加或刪除一個鏈接即可,速度快,線程不安全,效率高
Vector集合
底層數據結構是數組,查詢快,增刪慢,線程安全,效率低
2、Set集合
Hashset:
底層數據結構是哈希表,是根據哈希算法來存取對象的,存取速度快,當Hashset中元素個數超過數組大小(默認值位0.75)時,會進行近似兩倍的擴容,哈希表依賴兩個方法hashcode()和equals()方法,方法的執行順序,判斷hashcode值是否相同,是:執行equals方法看其返回值,true:說明元素重復不添加,false:直接添加到集合,hashcode值不相同直接添加到集合。
LinkedHashset:
底層數據結構是鏈表和哈希表,由鏈表保證元素有序,由哈希表保證元素的唯一
Treeset:
底層數據結構是紅黑樹(唯一,有序)由自然排序和比較器排序保證有序,根據返回值是否是0判斷元素是否唯一
3、Map集合
HashMap:
HashMap是基于散列表實現的,其插入和查詢的<k,v>的開銷是固定的,可以通過構造器設置容量和負載因子來調整容器的性能,線程不安全,效率低
TreeSet:
基于紅黑樹實現,查看<k,v>時,它們會被排序,TreeMap是唯一帶有subMap()方法的Map,subMap()方法可以返回一個子樹。
LInkedHashMap:
類似于HashMap,但是迭代遍歷它時,取得<K,V>的順序是其插入次序,或者是最近最少使用(LRU)的次序。
5.2 線程安全的集合
Vector、HashTable和java.util.concurrent包中的集合ConcurrentHashMap、CopyOnWriteArrayList和CopyOnWriteArraySet
5.3 hashMap的底層原理
HashMap是基于哈希表的Map接口的非同步實現。實現HashMap對數據的操作,允許有一個null鍵,多個null值。
HashMap底層就是一個數組結構,數組中的每一項又是一個鏈表。數組+鏈表結構,新建一個HashMap的時候,就會初始化一個數組。Entry就是數組中的元素,每個Entry其實就是一個key-value的鍵值對,它持有一個指向下一個元素的引用,這就構成了鏈表,HashMap底層將key-value當成一個整體來處理,這個整體就是一個Entry對象。HashMap底層采用一個Entry【】數組來保存所有的key-value鍵值對,當需要存儲一個Entry對象時,會根據hash算法來決定在其數組中的位置,在根據equals方法決定其在該數組位置上的鏈表中的存儲位置;當需要取出一個Entry對象時,也會根據hash算法找到其在數組中的存儲位置, 在根據equals方法從該位置上的鏈表中取出Entry;
5.4 hashMap和hashTable、currenthashMap區別
HashTable與HashMap、ConcurrentHashMap主要的區別在于HashMap不是同步的、線程不安全的和不適合應用于多線程并發環境下,而hashTable和ConcurrentHashMap是同步的也是線程安全的。hashtable是全局同步,每次修改都會鎖住整個對象而ConcurrentHashMap則會根據并發的等級來鎖住操作的那一段數據,ConcurrentHashMap有很好的擴展性,在多線程環境下性能方面比做了同步的HashMap要好,但是在單線程環境下,HashMap會比ConcurrentHashMap好一點。
5.5 ArrayList、vector、LinkedList的區別
5.5.1 從存儲數據結構分析
ArrayList和vector是數組,LinkedList是鏈表
5.5.2 從繼承上分析

5.5.3 從并發安全上分析
vector線程安全,ArrayList和linkedlist線程不安全。
5.5.4 數據增長分析
Vector:缺省的情況下,增長為原數組長度的一倍。說到缺省,說明他其實是可以自主設置初始化大小的。
ArrayList:自動增長原數組的50%
6.jvm內存模型的理解?
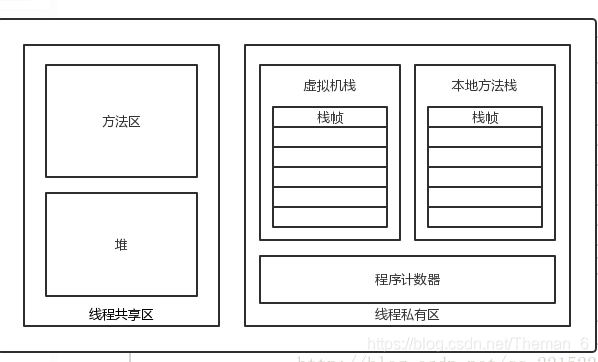
6.1 方法區(Method Area)
方法區主要是放一下類似類定義、常量、編譯后的代碼、靜態變量等,在JDK1.7中,HotSpot VM的實現就是將其放在永久代中,這樣的好處就是可以直接使用堆中的GC算法來進行管理,但壞處就是經常會出現內存溢出,即PermGen Space異常,所以在JDK1.8中,HotSpot VM取消了永久代,用元空間取而代之,元空間直接使用本地內存,理論上電腦有多少內存它就可以使用多少內存,所以不會再出現PermGen Space異常。
6.2 堆(Heap)
幾乎所有對象、數組等都是在此分配內存的,在JVM內存中占的比例也是極大的,也是GC垃圾回收的主要陣地,平時我們說的什么新生代、老年代、永久代也是指的這片區域,至于為什么要進行分代后面會解釋。
6.3 虛擬機棧(Java Stack)
當JVM在執行方法時,會在此區域中創建一個棧幀來存放方法的各種信息,比如返回值,局部變量表和各種對象引用等,方法開始執行前就先創建棧幀入棧,執行完后就出棧。
6.4 本地方法棧(Native Method Stack)
和虛擬機棧類似,不過區別是專門提供給本地Native方法用的。
6.5 程序計數器(Program Counter Register)
占用很小的一片區域,我們知道JVM執行代碼是一行一行執行字節碼,所以需要一個計數器來記錄當前執行的行數。
7 抽象類與接口的區別?
7.1 接口
接口是抽象方法的集合。如果一個類實現了某個接口,那么它就繼承了這個接口的抽象方法。這就像契約模式,如果實現了這個接口,那么就必須確保使用這些方法。接口只是一種形式,接口自身不能做任何事情
7.2 抽象類
抽象類是用來捕捉子類的通用特性的 。它不能被實例化,只能被用作子類的超類。抽象類是被用來創建繼承層級里子類的模板
區別

類是對事物的抽象,抽象類是對類的抽象,接口是對抽象類的抽象。接口用于抽象事物的特性,抽象類用于代碼復用。
8 volatile與synchronized的區別?
synchronized關鍵字解決的是執行控制的問題,它會阻止其它線程獲取當前對象的監控鎖,這樣就使得當前對象中被synchronized關鍵字保護的代碼塊無法被其它線程訪問,也就無法并發執行。更重要的是,synchronized還會創建一個內存屏障,內存屏障指令保證了所有CPU操作結果都會直接刷到主存中,從而保證了操作的內存可見性,同時也使得先獲得這個鎖的線程的所有操作
volatile關鍵字解決的是內存可見性的問題,會使得所有對volatile變量的讀寫都會直接刷到主存,即保證了變量的可見性。這樣就能滿足一些對變量可見性有要求而對讀取順序沒有要求的需求。
8.1
volatile本質是在告訴jvm當前變量在寄存器(工作內存)中的值是不確定的,需要從主存中讀取; synchronized則是鎖定當前變量,只有當前線程可以訪問該變量,其他線程被阻塞住。
8.2
volatile僅能使用在變量級別;synchronized則可以使用在方法和代碼塊
8.3
volatile僅能實現變量的修改可見性,不能保證原子性;而synchronized則可以保證變量的修改可見性和原子性
8.4
volatile不會造成線程的阻塞;synchronized可能會造成線程的阻塞。
8.5
volatile標記的變量不會被編譯器優化;synchronized標記的變量可以被編譯器優化
9 重寫與重載的區別?
方法的重載和重寫都是實現多態的方式,區別在于前者實現的是編譯時的多態性,而后者實現的是運行時的多態性。重載發生在一個類中,同名的方法如果有不同的參數列表(參數類型不同、參數個數不同或者二者都不同)則視為重載;重寫發生在子類與父類之間,重寫要求子類被重寫方法與父類被重寫方法有相同的參數列表,有兼容的返回類型,比父類被重寫方法更好訪問,不能比父類被重寫方法聲明更多的異常(里氏代換原則)。重載對返回類型沒有特殊的要求,不能根據返回類型進行區分。
10 java中字符串的方法有哪些?string、stringbuffer和stringbuilder的區別?
10.1 java中字符串的方法有哪些?
1、equals():比較兩個字符串是否相等
2、equalsIgnoreCase( ):忽略大小寫的兩個字符串是否相等比較
3、toString():轉換成String類型
4、String:轉換成String類型
5、String.valueOf():轉換成String類型(不用擔心object是否為null值這一問題)
6、split():分隔符
7、subString():截取字符串中的一段字符串
8、charAt():返回指定索引處char值
9、toLowerCase():將所有在此字符串中的字符轉化為小寫(使用默認語言環境的規則)
10、indexOf():指出 String 對象內子字符串的開始位置
11、replace和replaceAll
12、getBytes():得到一個系統默認的編碼格式的字節數組
13、StringBuffer的append方法
10.2string、stringbuffer和stringbuilder的區別?

總結
以上是生活随笔為你收集整理的Java基础知识1-10的全部內容,希望文章能夠幫你解決所遇到的問題。

- 上一篇: 2023-08-06:小青蛙住在一条河边
- 下一篇: ThinkPHP公共配置文件与各自项目中